

Scénario :
Un responsable des admissions doit recevoir quatre documents requis de la part de chaque étudiant. Comment pouvons-nous créer un flux de travail pour détecter les documents requis dans un processus ?
Solution :
Créer un processus de flux de travail pour détecter les documents requis manquants dans une armoire est en effet possible. Veuillez vous référer à l'exemple suivant pour savoir comment procéder.
Dans cet exemple, les étudiants de ce système auront quatre documents requis à comptabiliser, à savoir l'emploi du temps de l'étudiant, les notes et relevés de notes, l'acte de naissance et le dossier d'orientation.
Note : Cette logique de flux de travail est un exemple de la manière dont ce processus peut être mis en place.Les étapes peuvent être modifiées pour mieux s'adapter à votre système.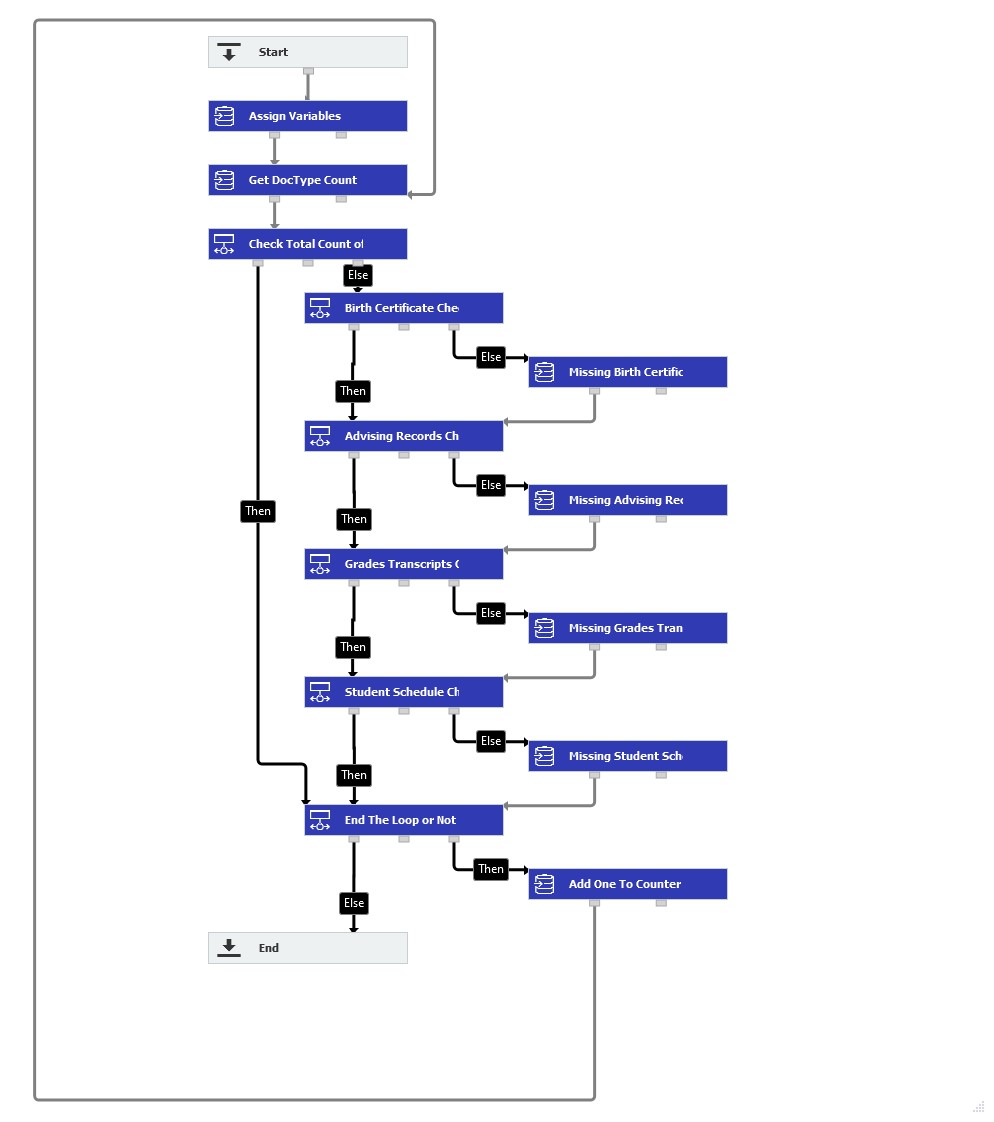
1. Lors de la création de ce flux de travail, les conditions de déclenchement suivantes ont été utilisées. L'utilisation de cette condition de déclenchement nous permet de stocker un enregistrement de données dans l'armoire des dossiers d'étudiants, de mettre à jour le champ Statut pour déclencher l'exécution manuelle du flux de travail. Le champ de mots-clés Docs manquants contiendra alors les résultats.
Start new workflow = if index entries of the document were changed
Status = is empty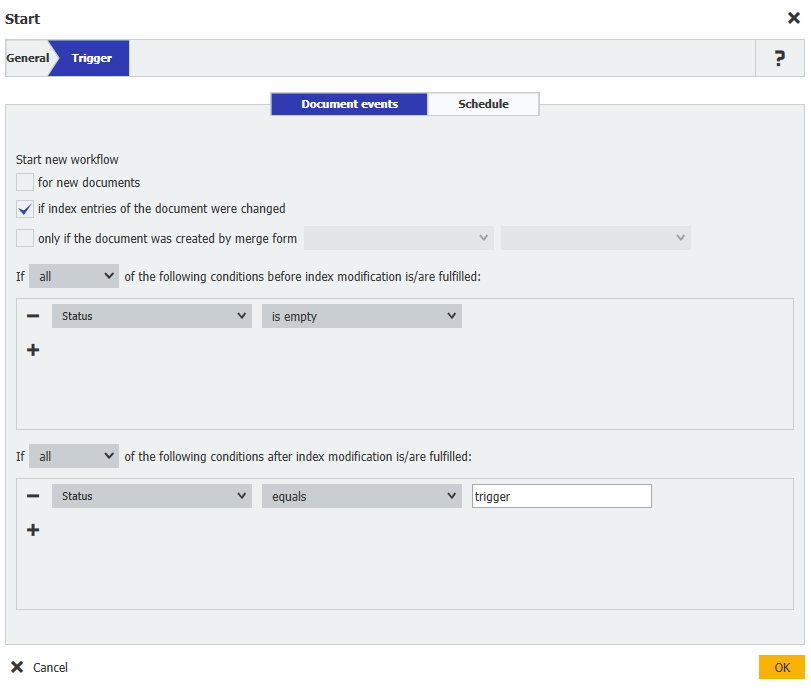
2. Une fois les conditions de déclenchement définies, la création des variables globales suivantes sera nécessaire pour ce flux de travail.
Type de texte Variables globales
- Contient
- Nom de l'étudiant
- Nom de l'étudiant
Type Integer Variables globales
- Compte
- Compteur
- DocID
Type de mot-clé Variables globales
- DocTypes
- Liste des étudiants
Notre exemple comporte également un classeur nommé Fichiers étudiants, qui contient les champs suivants.
Type de texte
- Type de document
- Étudiant
- Statut
Type de mot-clé
- Documents manquants
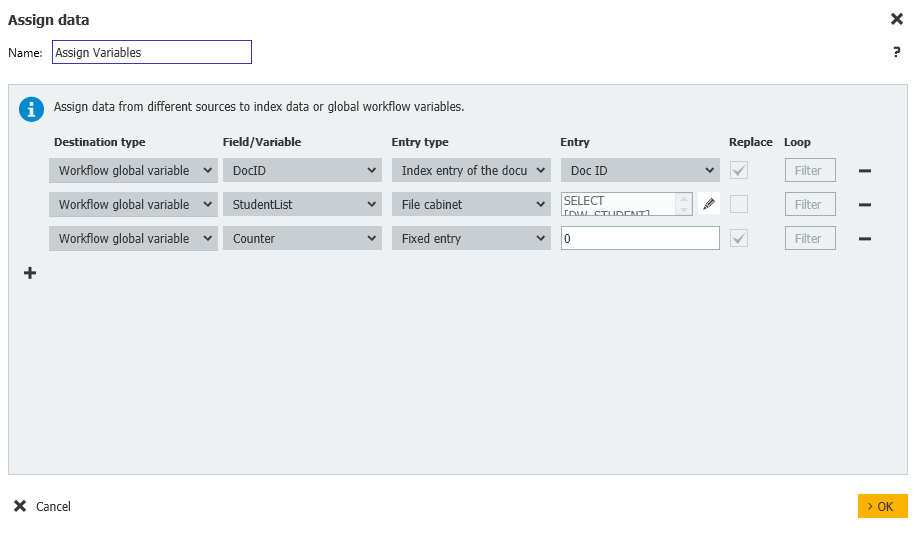
3. Une fois les variables ajoutées, créez une étape d'affectation des données, que nous avons nommée "Affectation des variables", avec les affectations suivantes.
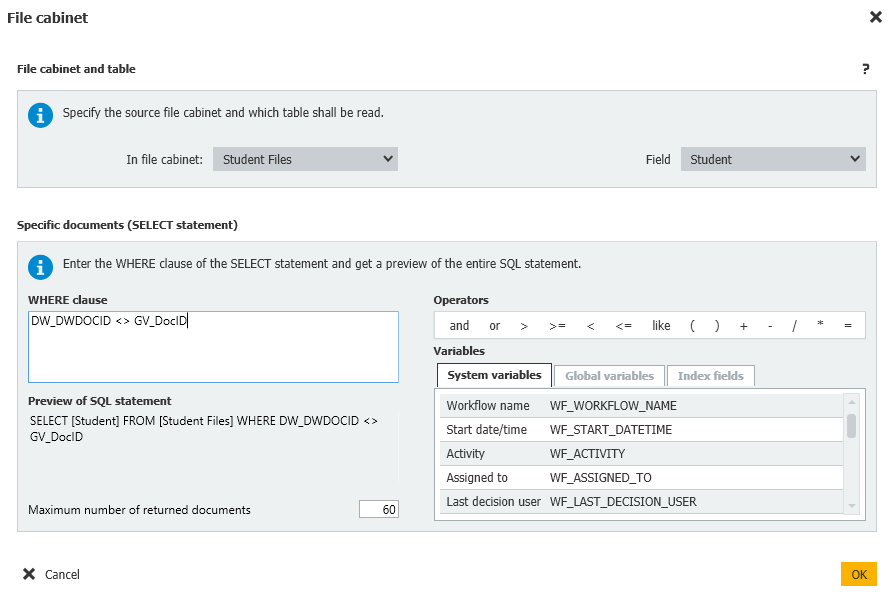
Workflow global variable = StudentList = File cabinet = DW_DWDOCID < > GV_DocID
Workflow global variable = Counter = Fixed entry = 0
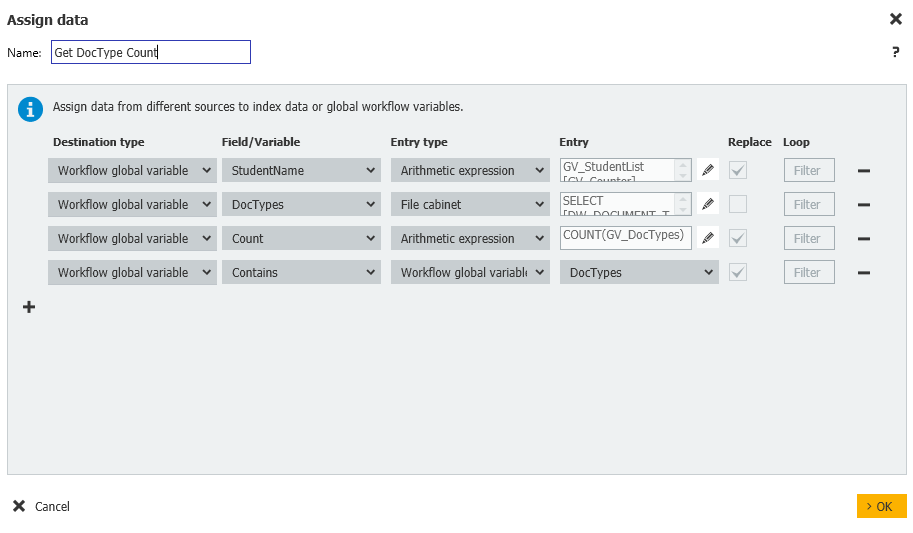
4. Ensuite, créez une autre étape d'assignation de données nommée "Get DocType Count", qui obtiendra notre liste d'étudiants à vérifier et le nombre total de types de documents stockés dans l'armoire.
Cette étape contient les assignations suivantes.
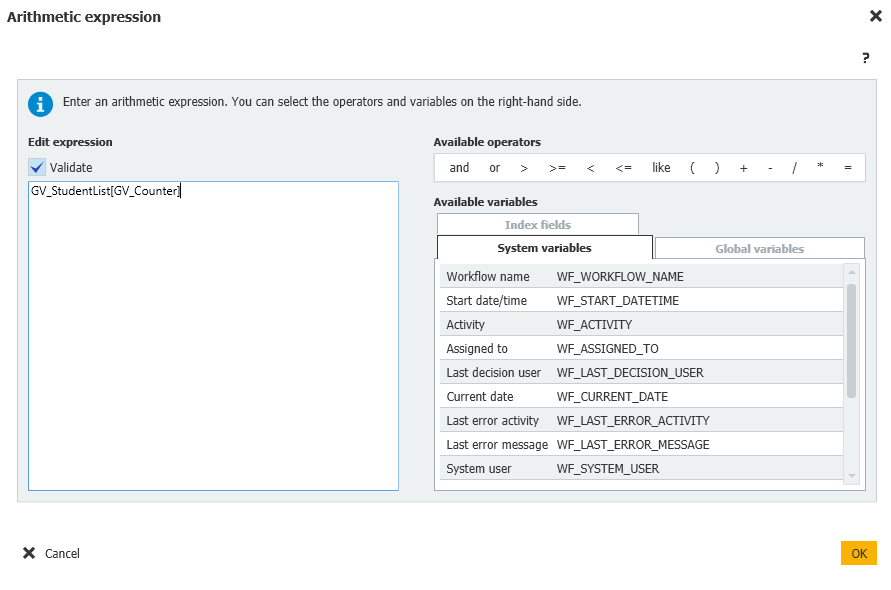
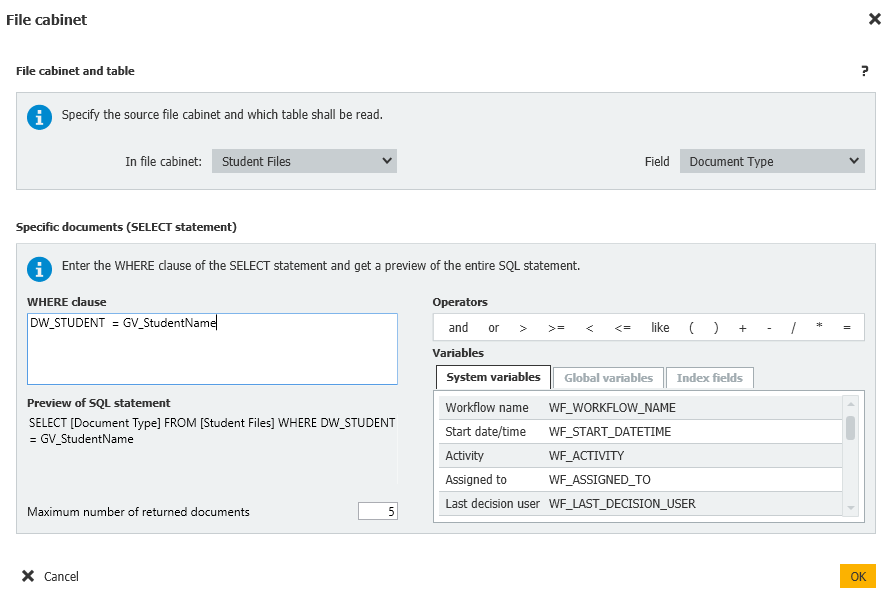
Workflow global variable = DocTypes = File cabinet = DW_StudentName = GV_StudentName
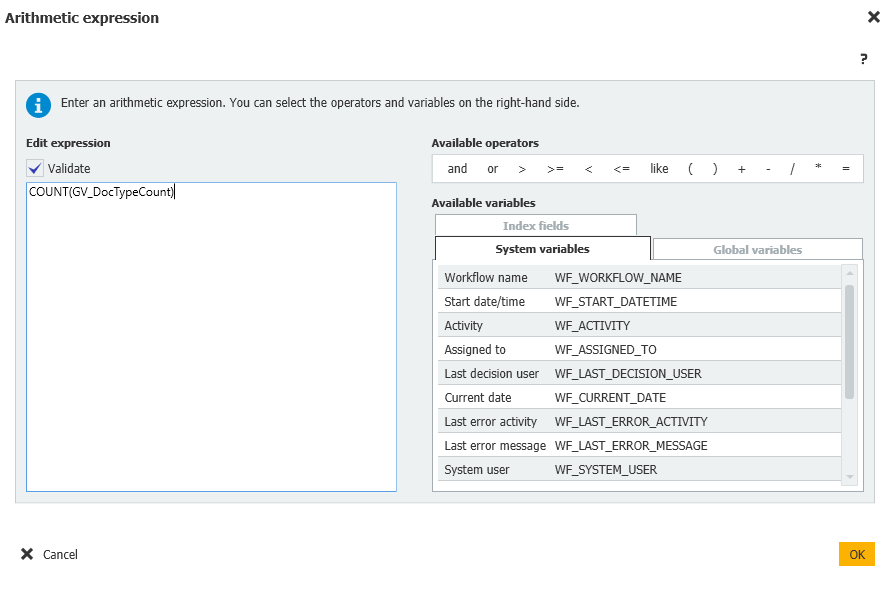
Workflow global variable = Count = Arithmetic expression = COUNT(GV_DocTypes)
Workflow global variable = Contains = Workflow global variable = DocTypes
5. Notre prochaine étape sera une Condition, où nous vérifierons si tous les documents ont été trouvés pour un étudiant donné. Si tous les documents sont trouvés, nous passerons à l'étudiant suivant.
Dans notre exemple, puisque 4 types de documents sont attendus, nous comparons notre nombre à 4. Modifiez cette valeur en fonction de votre système. Sinon, nous passerons à une section du flux de travail pour vérifier chaque type de document afin de déterminer lequel est manquant pour l'étudiant.
Condition : GV_Count = 4
Condition remplie : Alors
Condition non remplie : Else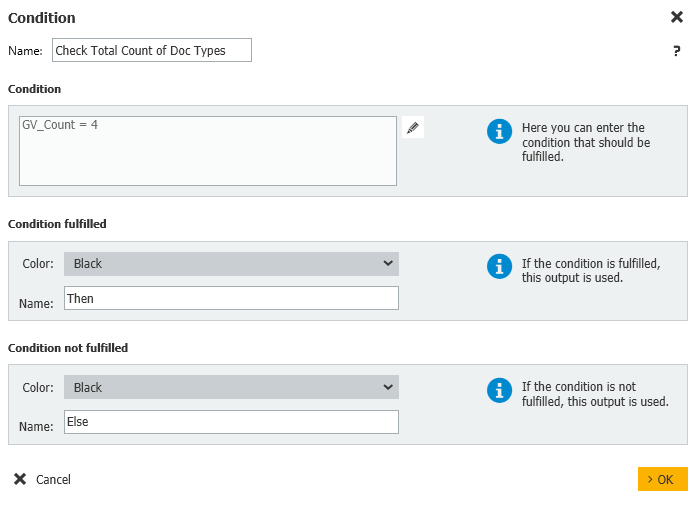
6. Ensuite, nous vérifions si le type de document "acte de naissance" figure dans la liste des types de documents recherchés pour cet étudiant. Si c'est le cas, nous passons au type de document suivant ; sinon, nous ajoutons le type de document au champ d'index "Documents manquants" et passons à l'étape d'affectation des données. Après avoir exécuté le flux de travail, vous pouvez vérifier cette zone pour tous les documents manquants dans l'enregistrement de données.
Les informations suivantes montrent comment ces deux étapes sont configurées pour chaque type de document.
Condition : GV_Contains like "%Birth Certificate%"
Condition remplie : Alors
Condition non remplie : Else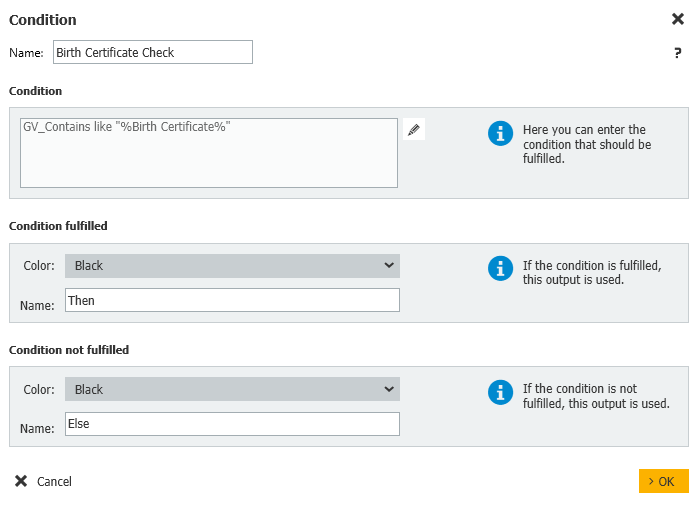
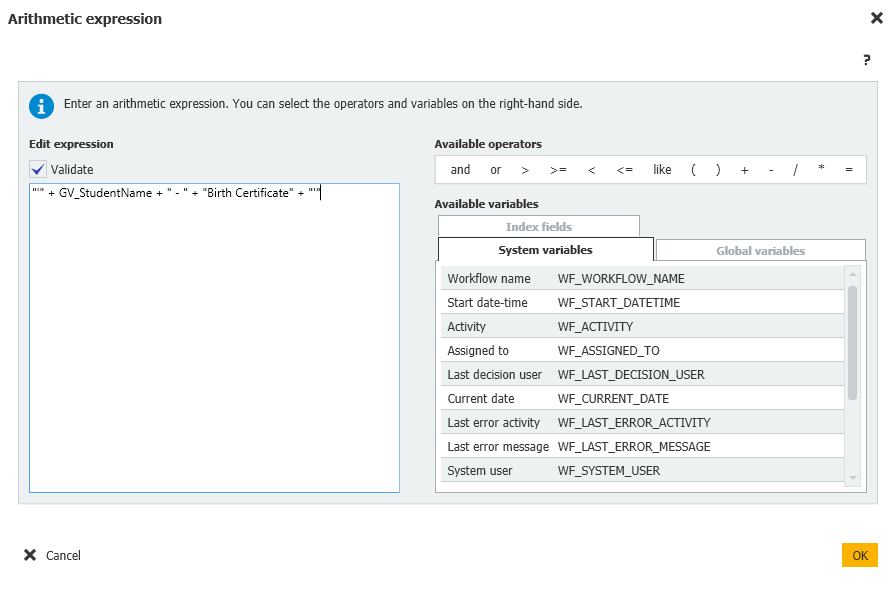
Données d'index du document = manquantes Docs = Expression arithmétique = "" + GV_StudentName + " - " + "Birth Certificate" + ""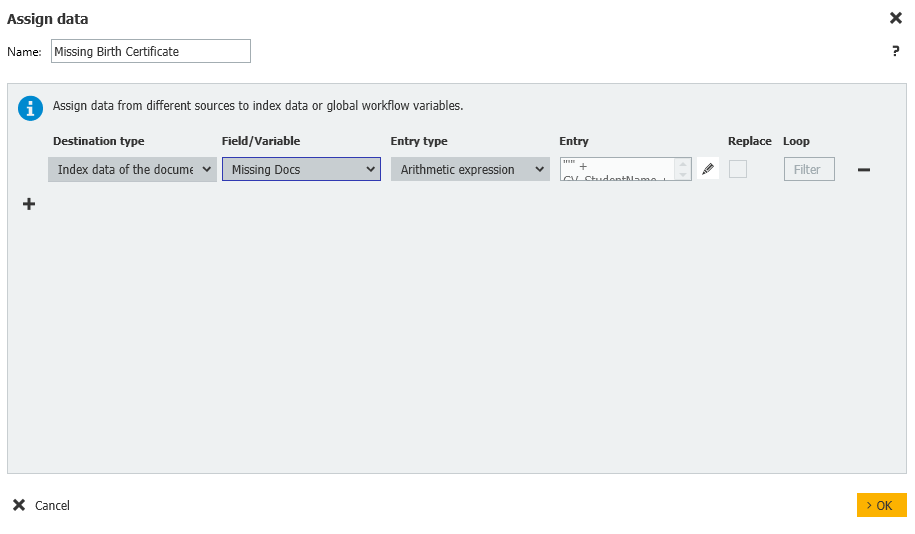
7. Cette configuration est répétée pour les autres types de documents. Une fois que tous les types de documents ont été vérifiés, tout document manquant sera ajouté à notre champ de mots-clés Docs manquants, puis nous passerons à l'étape de la condition intitulée "Terminer la boucle ou non".
Cette condition vérifiera s'il y a encore des étudiants à traiter ou non.
Condition : GV_Counter + 1 < COUNT(GV_StudentList)
Condition remplie : Then
Condition non remplie : Else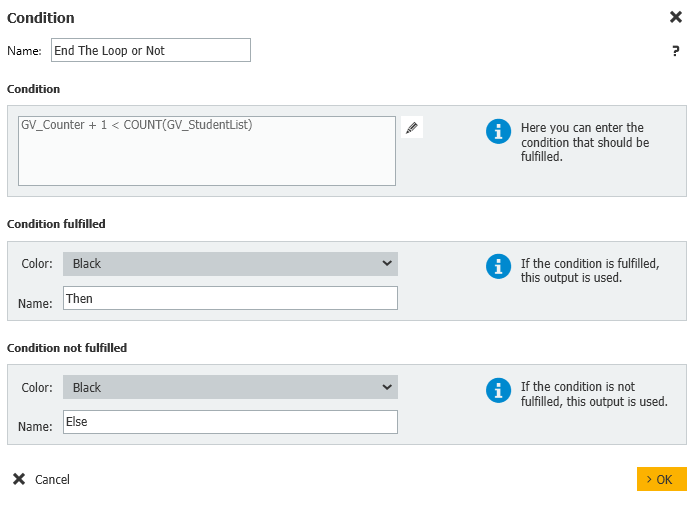
8. S'il n'en reste aucun, nous quitterons le flux de travail. Dans le cas contraire, nous passerons à une étape d'affectation des données au cours de laquelle nous ajouterons un à notre variable compteur, puis nous répéterons le flux de travail en vérifiant s'il manque des documents pour l'étudiant suivant.
Workflow global variable = DocTypes = Fixed entry = NULL
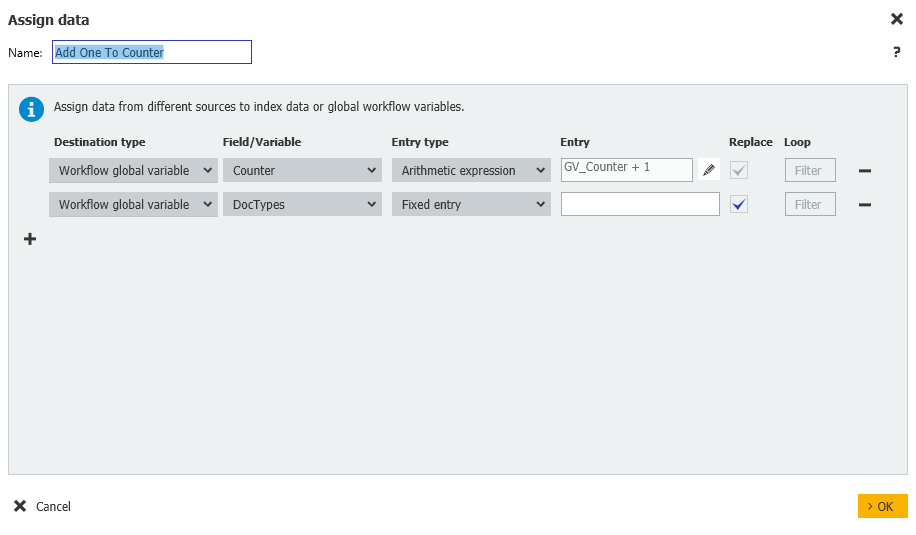
Remarquez que nous effaçons également la variable globale DocTypes car nous aurons besoin d'une table rase pour traiter l'utilisateur suivant.
Une fois ce flux de travail sauvegardé et publié, il se déroulera comme suit ;
- Stocker un enregistrement de données dans l'armoire des fichiers étudiants. (Cette opération ne doit être effectuée qu'une seule fois)
- Une fois stocké, ouvrez l'enregistrement de données, saisissez "Déclencher" dans le champ Statut pour déclencher manuellement le flux de travail et fermez l'enregistrement de données.
- Après quelques instants, lorsque vous ouvrirez l'enregistrement de données, le champ Documents manquants contiendra une liste d'étudiants et les documents qui leur manquent.
Si vous devez réexécuter ce processus à l'avenir, veillez à effacer toutes les entrées du champ Documents manquants et Statut, puis répétez les étapes 2 et 3.
Le KBA s'applique aussi bien aux organisations en nuage qu'aux organisations sur site.
Veuillez noter : Cet article est une traduction de l'anglais. Les informations contenues dans cet article sont basées sur la ou les versions originales des produits en langue anglaise. Il peut y avoir des erreurs mineures, notamment dans la grammaire utilisée dans la version traduite de nos articles. Bien que nous ne puissions pas garantir l'exactitude complète de la traduction, dans la plupart des cas, vous la trouverez suffisamment informative. En cas de doute, veuillez revenir à la version anglaise de cet article.