

Scenario:
入試担当者は、各学生から4つの必要書類を受け取る必要がある。プロセス内で必要書類を検出するワークフローをどのように作成できますか?
解決策:
ファイルキャビネットから紛失した必要書類を検出するワークフロープロセスを作成することは、確かに可能です。以下の例を参照してください。
この例では、このシステムの学生には、「学生スケジュール」、「成績/成績証明書」、「出生証明書」、「アドバイジングレコード」の4つの必要書類があります。
注:このワークフローロジックは、このプロセスがどのようにセットアップされるかの例です。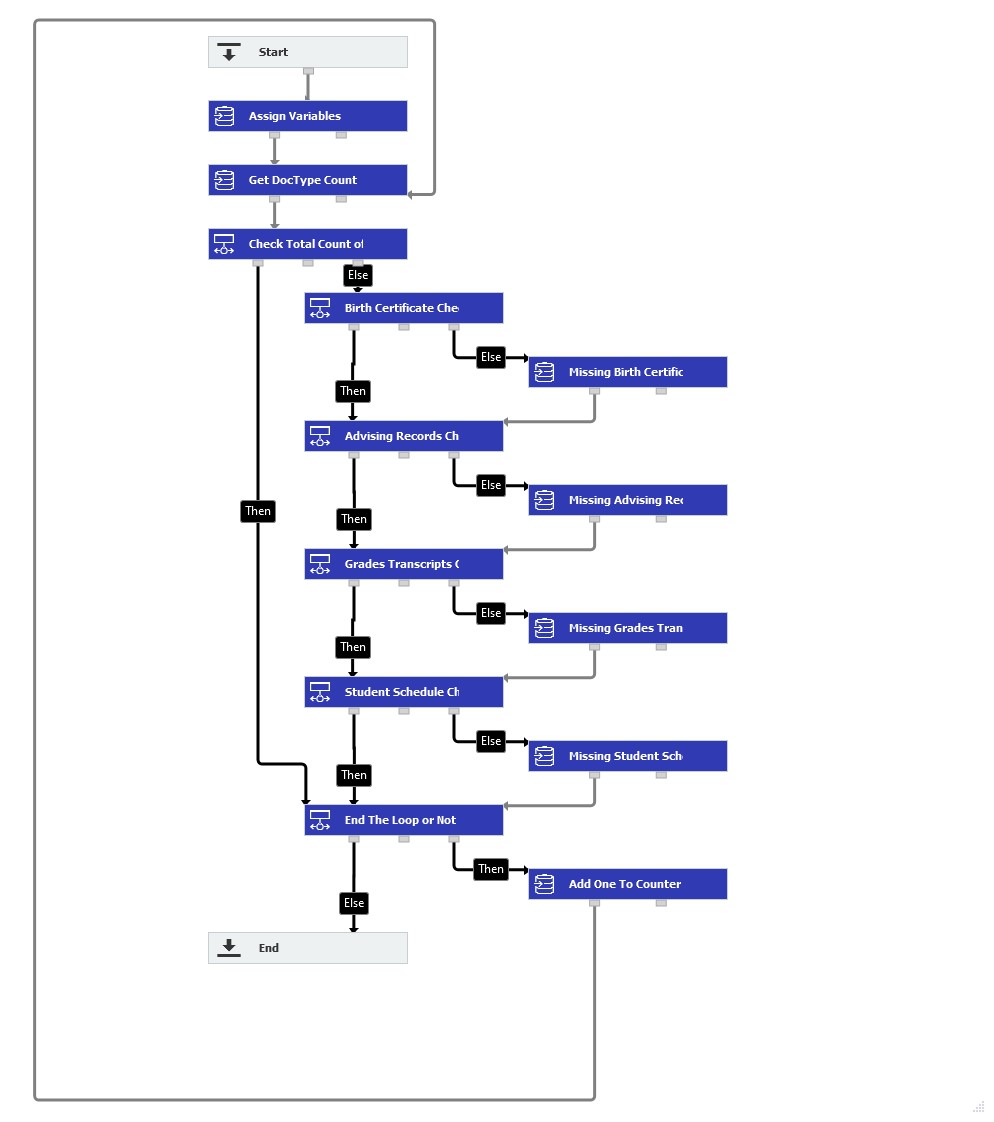
1.このワークフローを作成する際、以下のトリガー条件を使用します。このトリガー条件を利用することで、Student Filesファイルキャビネットにデータレコードを保存し、Status フィールドを手動でワークフローを実行するトリガーに更新することができます。
Start new workflow = if index entries of the document were changed
Status = is empty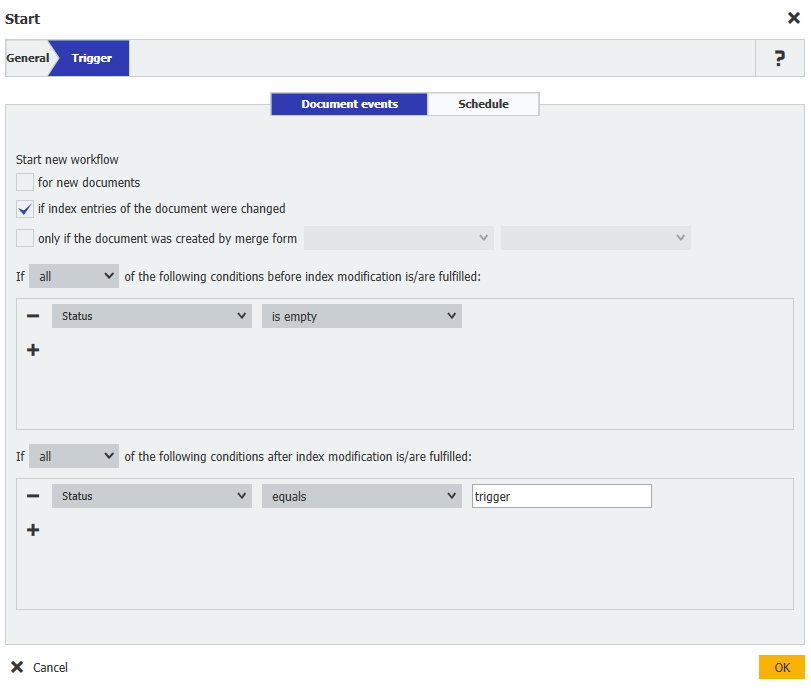
2.
テキストタイプ グローバル変数
- 内容
- StudentName
- StudentNames
整数型 グローバル変数
- Count
- カウンタ
- DocID
キーワード型 グローバル変数
- Doc型
- 学生リスト
この例では、Student Filesという名前のFile Cabinetもあり、以下のフィールドがあります。
テキスト型
- ドキュメントタイプ
- 学生
- ステータス
キーワードタイプ
- 見つからないドキュメント
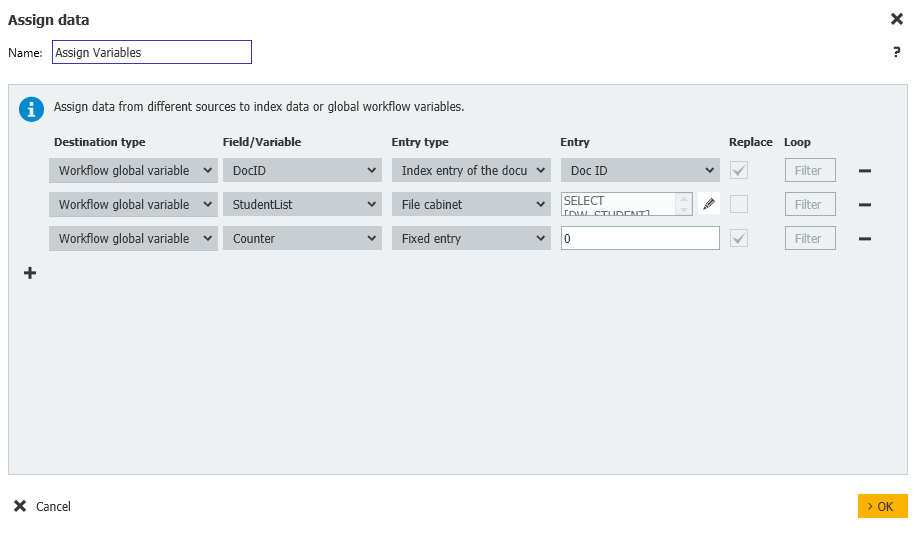
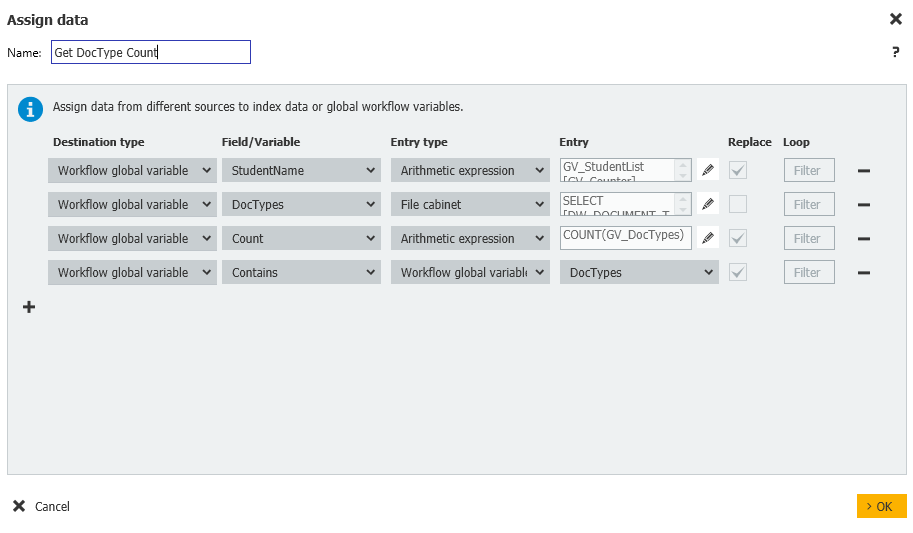
3.変数が追加されたら、"Assign Data "ステップを作成する。"Assign Variables"と名付け、以下の割り当てを行う。
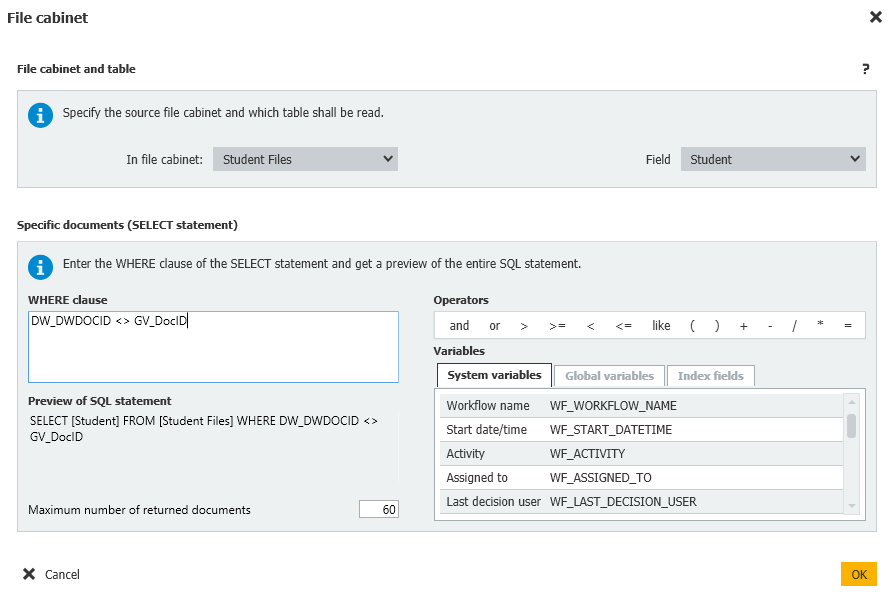
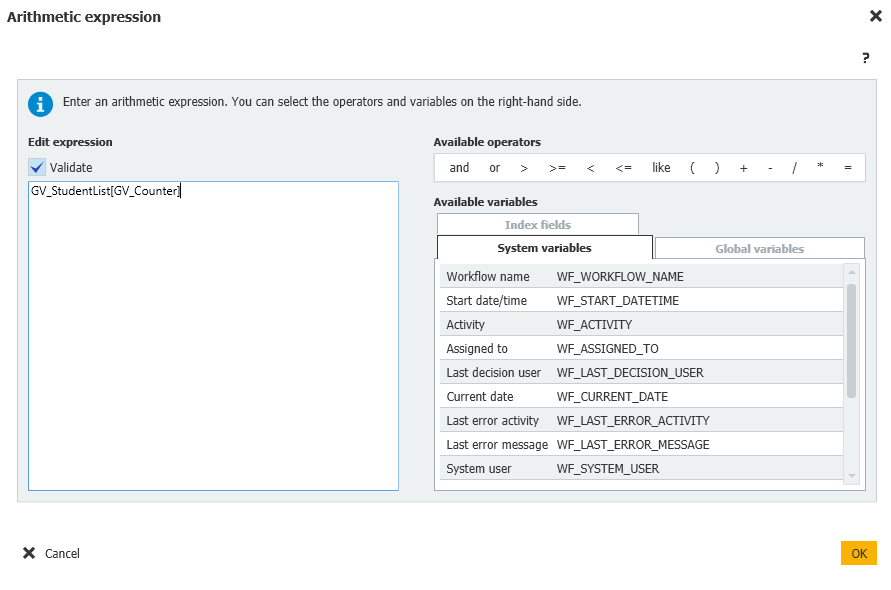
Workflow global variable = StudentList = File cabinet = DW_DWDOCID < > GV_DocID
Workflow global variable = Counter = Fixed entry = 0
4.次に、"Get DocType Count"という名前の別のデータ割り当てステップを作成します。このステップでは、チェックするStudentのリストと、ファイルキャビネットに保存されているドキュメントタイプの総カウントを取得します。
このステップには、以下の割り当てが含まれています。
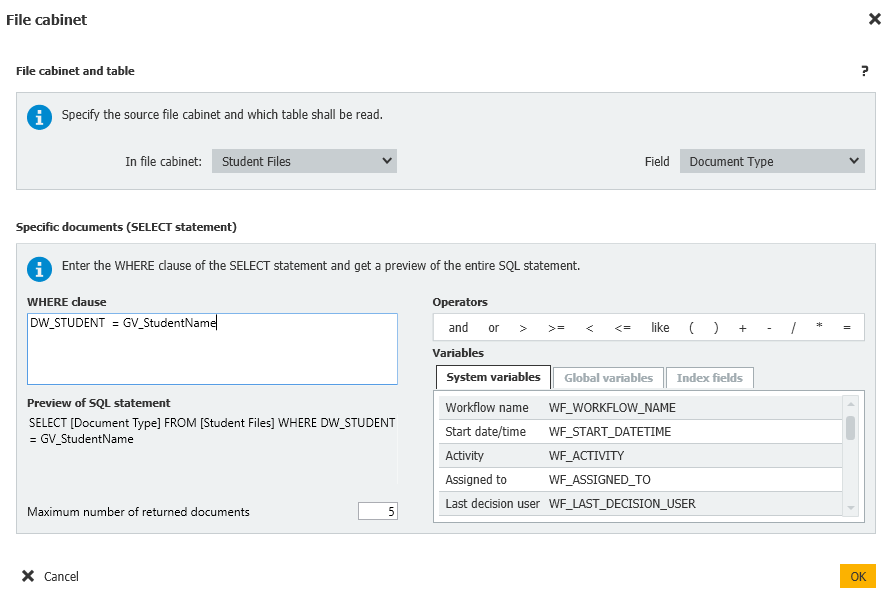
Workflow global variable = DocTypes = File cabinet = DW_StudentName = GV_StudentName
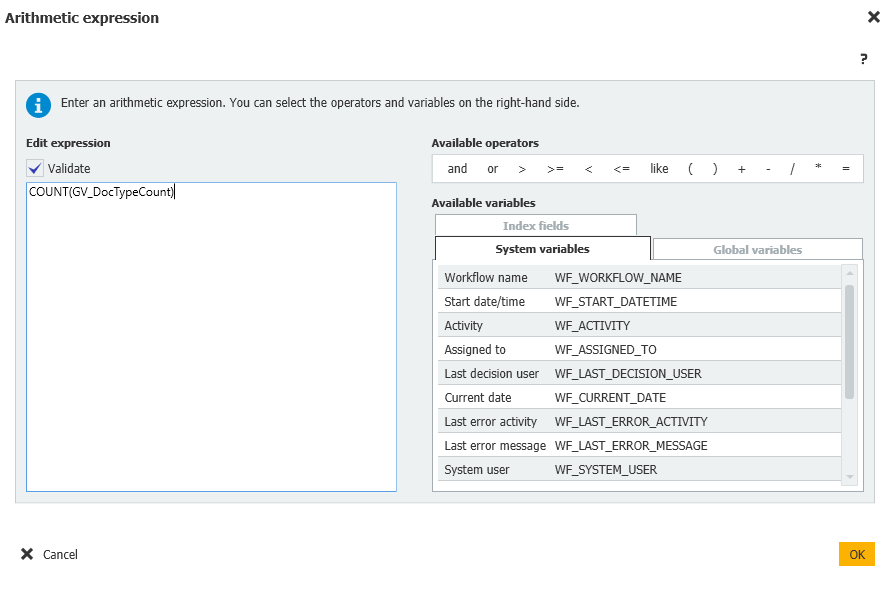
Workflow global variable = Count = Arithmetic expression = COUNT(GV_DocTypes)
Workflow global variable = Contains = Workflow global variable = DocTypes
5.次のステップは「条件」であり、指定された学生について、すべてのドキュメントが説明され ているかどうかをチェックします。すべてのドキュメントが見つかった場合、次の学生に進みます。
この例では4つのドキュメントタイプが期待されているので、Countを4と比較します。そうでない場合は、ワークフローセクションに分かれて、各ドキュメントタイプに対してチェックし、学生のどれが欠けているかを判断します。
条件:GV_Count = 4
条件が満たされた:その後
条件が満たされない:Else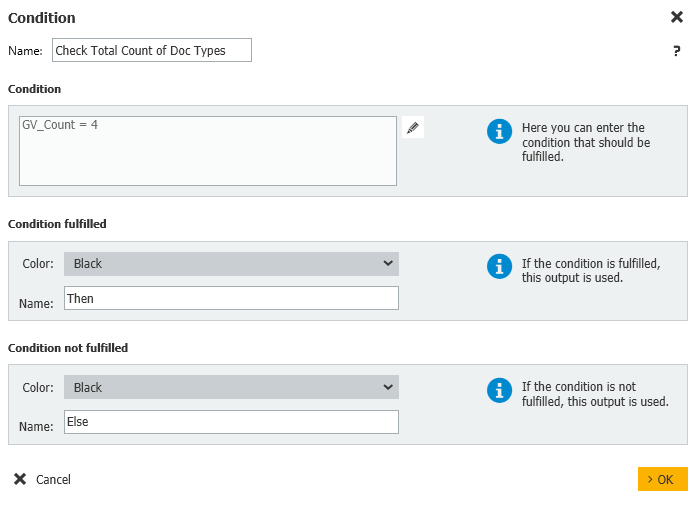
6. 次に、Birth Certificate(出生証明書)の文書タイプが、この学生の検索された文書タイプリストにあるかどうかを確認します。見つかった場合、次のドキュメントタイプに移ります。そうでない場合、ドキュメントタイプをインデックスフィールド「Missing Docs」に追加し、データの割り当てステップに進みます。ワークフローを実行した後、このフィールドをチェックすることで、データレコードに欠落しているすべてのドキュメントを確認することができます。
以下の情報は、各文書タイプに対してこの2つのステップがどのように設定されているかを示しています。
条件GV_Contains like "%Birth Certificate%"
条件成立:その後
条件が満たされない:Else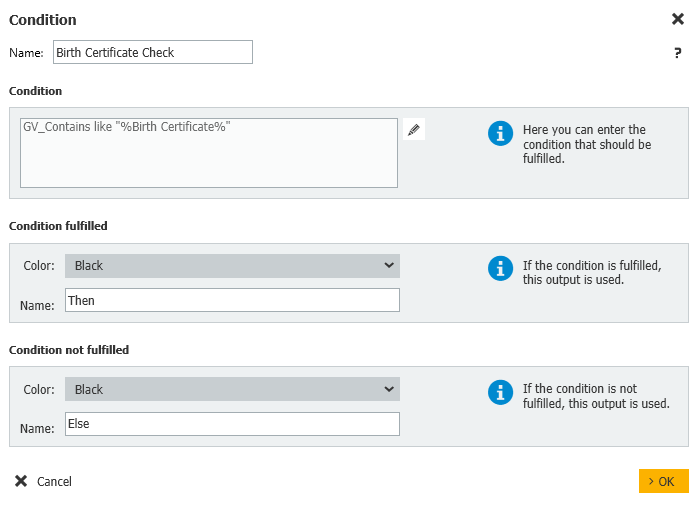
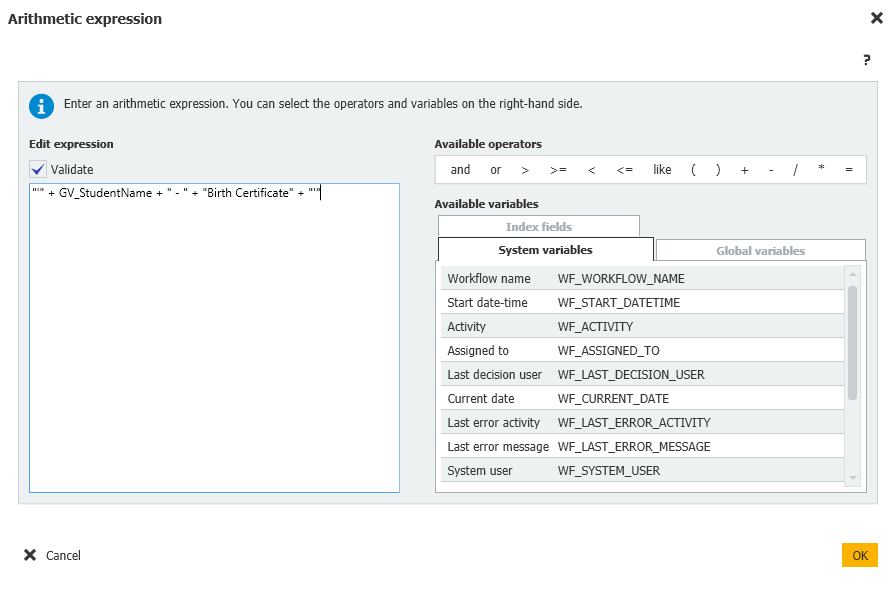
文書のインデックスデータ = 欠落 Docs = 算術式 = "" + GV_StudentName + " - " + "出生証明書" + ""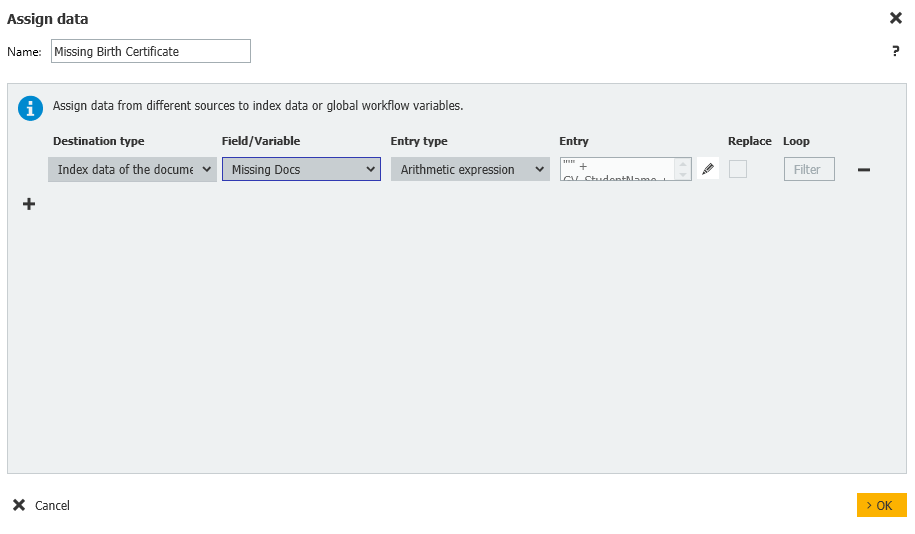
7.この設定を残りの文書タイプについて繰り返す。すべてのドキュメントタイプがチェックされると、欠落が見つかったものはMissing Docsキーワードフィールドに追加され、"ループを終了するかどうか"
この条件は、まだ処理する必要がある学生がいるかどうかをチェックします。
条件GV_Counter + 1 < COUNT(GV_StudentList)
条件が満たされた:Then
条件不成立:Else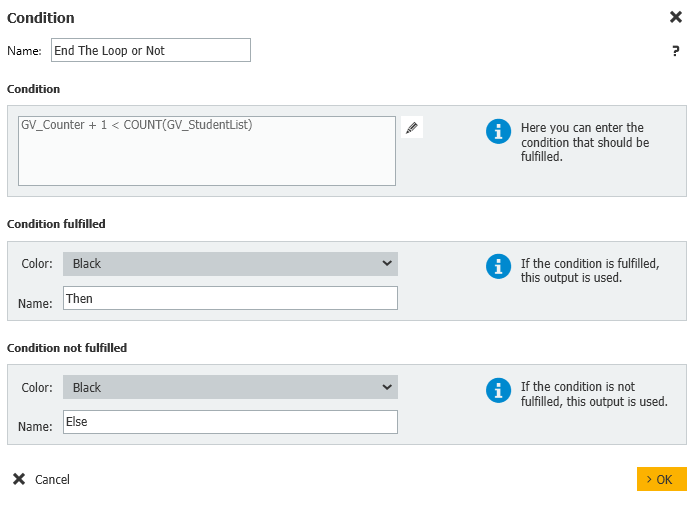
8.何も残っていなければ、ワークフローを終了する。そうでなければ、カウンタ変数に1つ追加するデータ割り当てステップに移行し、ワークフローを繰り返し、次の学生のドキュメントがないかチェックします。
Workflow global variable = DocTypes = Fixed entry = NULL
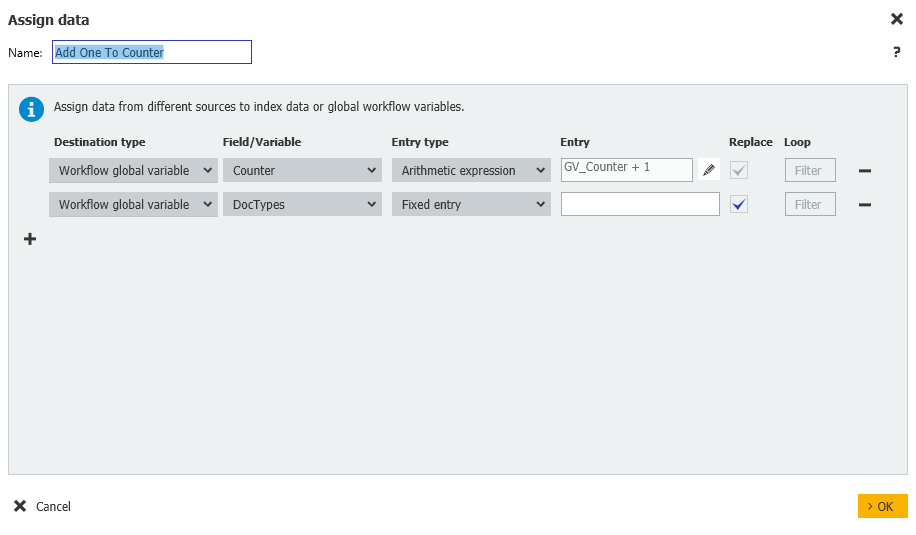
DocTypesグローバル変数もクリアすることに注意してください。
このワークフローを保存し、パブリッシュすると、ワークフローは以下のように進行する;
- Student Filesファイルキャビネットにデータレコードを保存します。(データレコードをStudent Filesファイルキャビネットに保存する。)
- 保存後、データレコードを開き、ワークフローを手動でトリガーするため、ステータスフィールドに「Trigger」と入力し、データレコードを閉じる。
- しばらくしてデータレコードを開くと、「不足している書類」フィールドに学生のリストとどの書類が不足しているかが表示されます。
今後このプロセスを再実行する必要がある場合は、欠落している書類およびステータスフィールドからすべてのエントリを消去し、ステップ2と3を繰り返してください。
KBAはクラウドとオンプレミスの両方の組織に適用できます。
ご注意:この記事は英語からの翻訳です。この記事に含まれる情報は、オリジナルの英語版製品に基づくものです。翻訳版の記事で使用されている文法などには、細かい誤りがある場合があります。翻訳の正確さを完全に保証することは出来かねますが、ほとんどの場合、十分な情報が得られると思われます。万が一、疑問が生じた場合は、英語版の記事に切り替えてご覧ください。