

Escenario:
Un oficial de admisiones necesita recibir cuatro documentos requeridos de cada estudiante. ¿Cómo podemos crear un flujo de trabajo para detectar los documentos requeridos dentro de un proceso?
Solución:
Crear un proceso de flujo de trabajo para detectar los documentos requeridos que faltan en un archivador sí es posible. Consulte el siguiente ejemplo de cómo podría hacerse.
En este ejemplo, los estudiantes en este sistema tendrán cuatro documentos requeridos para ser contabilizados, los cuales son Horario del Estudiante, Calificaciones/Transcripciones, Certificado de Nacimiento y Registros de Asesoría.
Nota: Esta lógica de flujo de trabajo es un ejemplo de cómo este proceso puede ser configurado.Los pasos pueden ser modificados para adaptarse mejor a su sistema.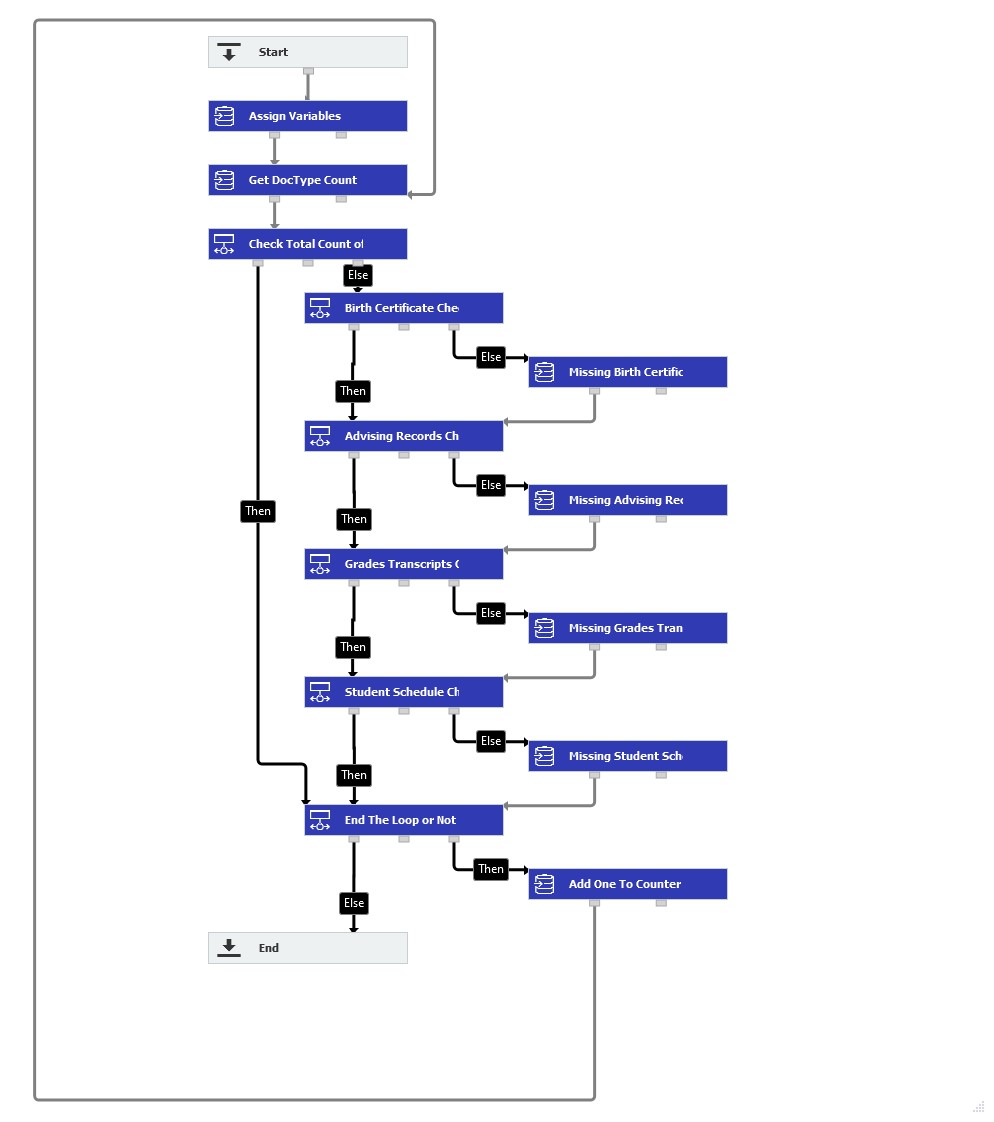
1. Al crear este flujo de trabajo, siga los siguientes pasos Al crear este flujo de trabajo, se utilizaron las siguientes condiciones de activación. La utilización de esta condición de activación nos permitirá almacenar un registro de datos en el archivador Archivos de Estudiante, actualizar el campo Estado para activar la ejecución manual del flujo de trabajo. A continuación, el campo de palabra clave Missing Docs contendrá los resultados.
Start new workflow = if index entries of the document were changed
Status = is empty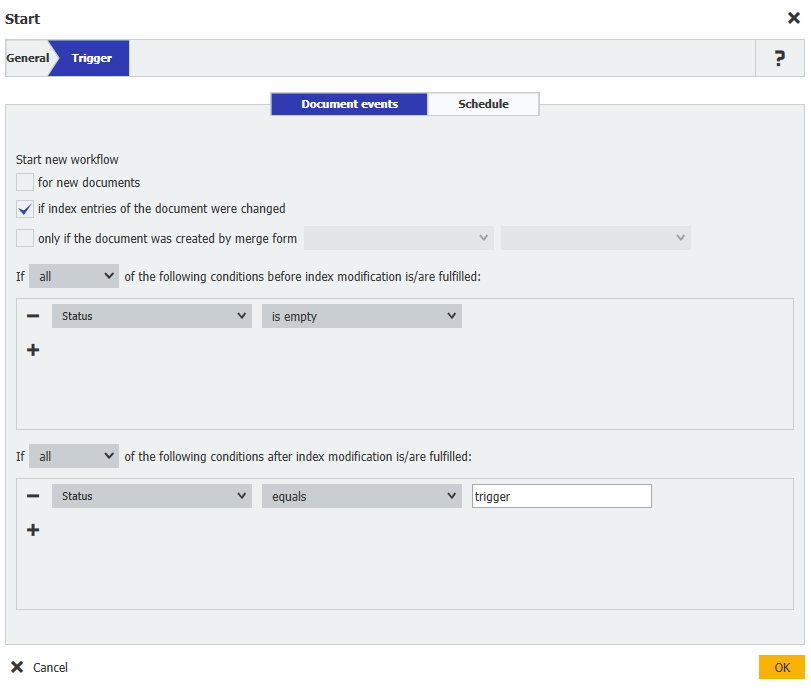
2. Condiciones desencadenantes. Una vez establecidas las condiciones de activación, será necesario crear las siguientes variables globales para este flujo de trabajo.
Tipo de texto Variables globales
- Contiene
- NombreAlumno
- NombreEstudiante
Variables globales de tipo entero
- Cuenta
- Contador
- DocID
Tipo de palabra clave Variables globales
- Tipos de documento
- StudentList
Nuestro ejemplo también tiene un archivador llamado Student Files, que contiene los siguientes campos.
Tipo de texto
- Tipo de documento
- Estudiante
- Estado
Tipo de palabra clave
- Documentos que faltan
3. Una vez añadidas las variables, cree un paso Asignar Datos, al que hemos llamado "Asignar Variables" con las siguientes asignaciones.
Workflow global variable = DocID = Index entry of the document = Doc ID
Workflow global variable = StudentList = File cabinet = DW_DWDOCID < > GV_DocID
Workflow global variable = Counter = Fixed entry = 0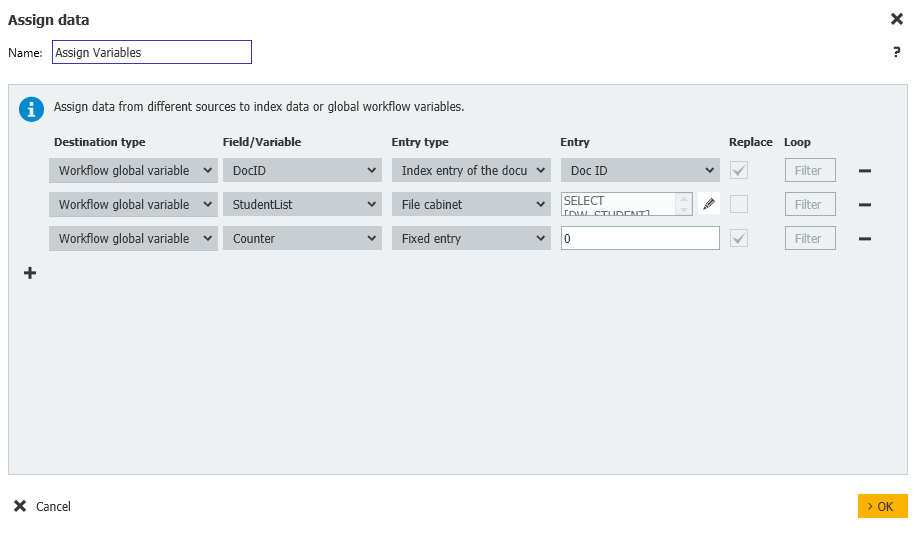
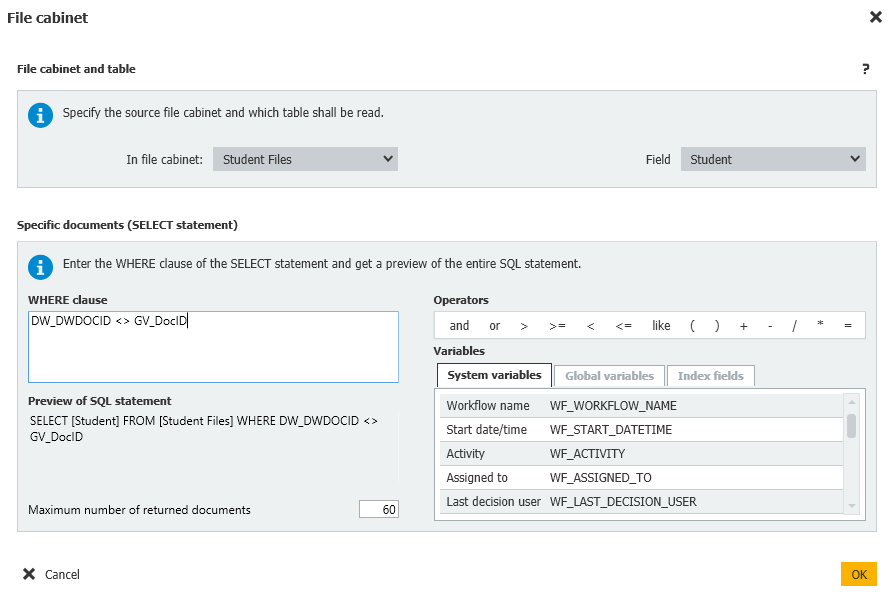
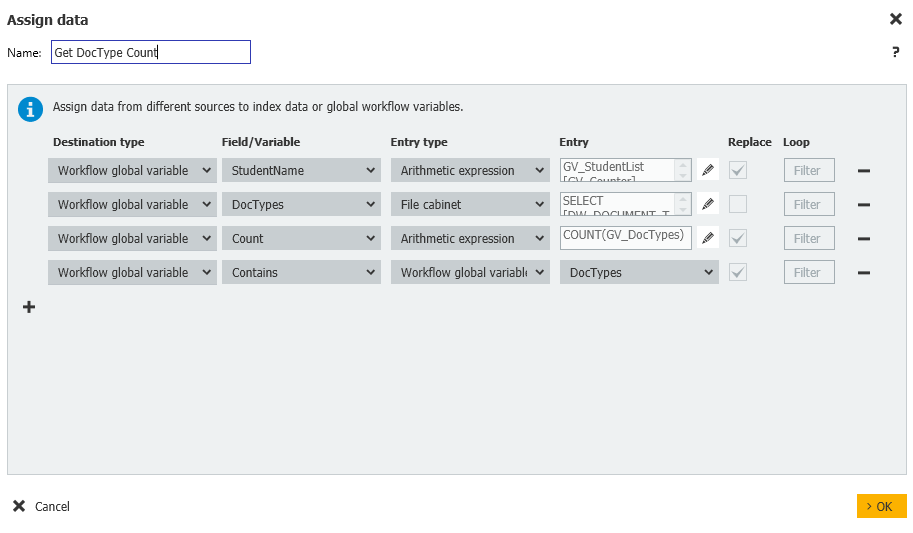
4. A continuación, cree otro paso Asignar datos denominado "Obtener recuento de tipos de documentos", que obtendrá nuestra lista de Estudiantes para comprobar y el recuento total de tipos de documentos almacenados en el archivador.
Este paso contiene las siguientes asignaciones.
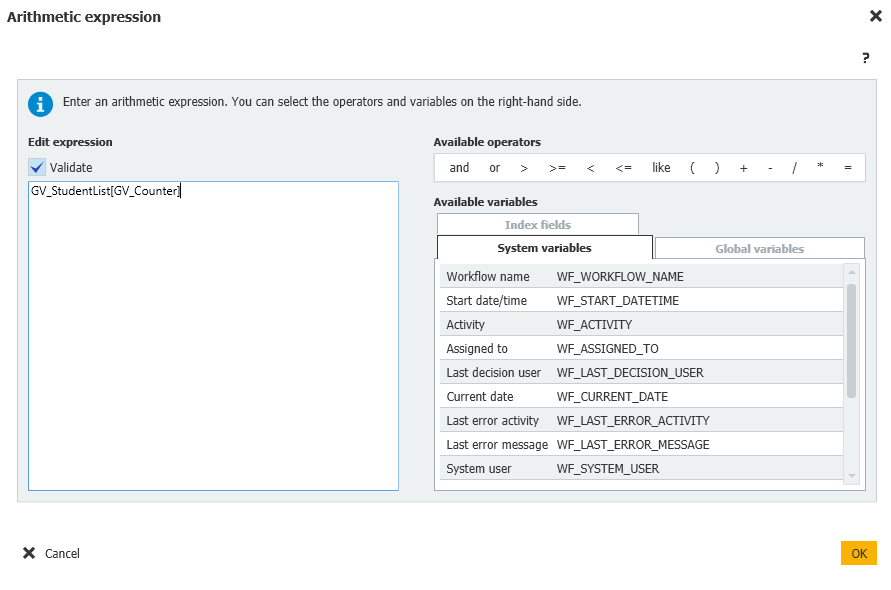
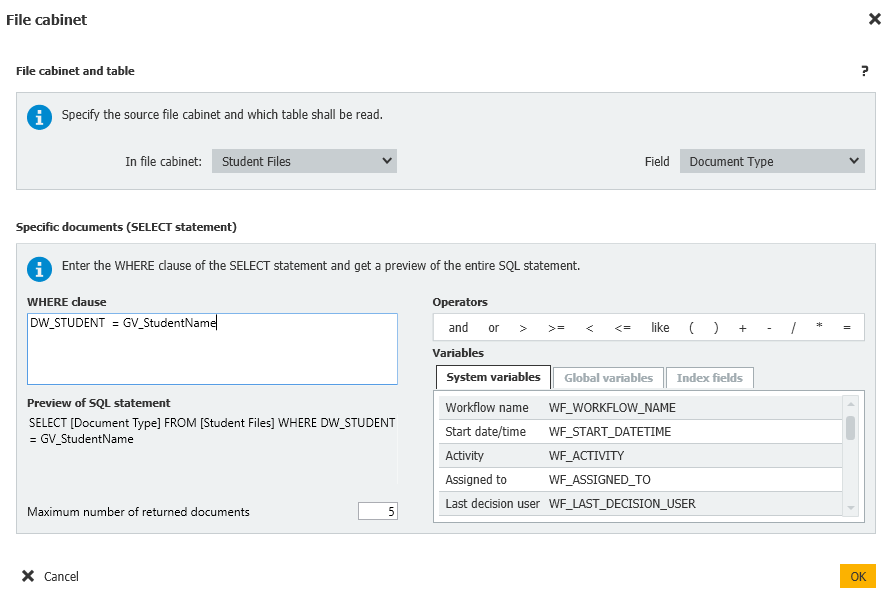
Workflow global variable = DocTypes = File cabinet = DW_StudentName = GV_StudentName
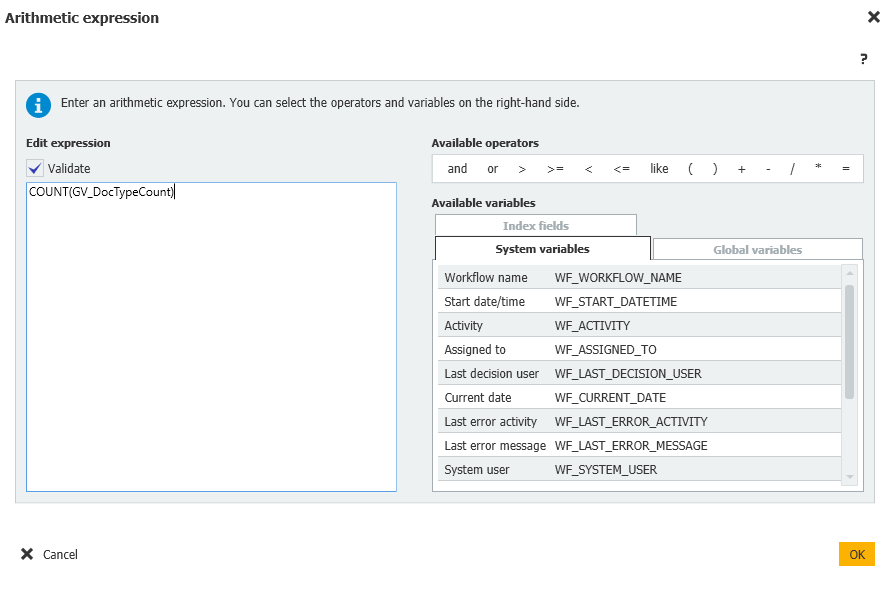
Workflow global variable = Count = Arithmetic expression = COUNT(GV_DocTypes)
Workflow global variable = Contains = Workflow global variable = DocTypes
5. Nuestro siguiente paso será una Condición, en la que comprobaremos si se han contabilizado todos los documentos de un alumno determinado. Si se encuentran todos los documentos, pasaremos al siguiente alumno.
En nuestro ejemplo, como se esperan 4 tipos de documentos, comparamos nuestro Recuento con 4. Cambie esto según su sistema. De lo contrario, nos dividiremos en una sección de flujo de trabajo para comprobar cada tipo de documento y determinar cuál falta para el estudiante.
Condition: GV_Count = 4
Condición cumplida: Entonces
Condición no cumplida: Else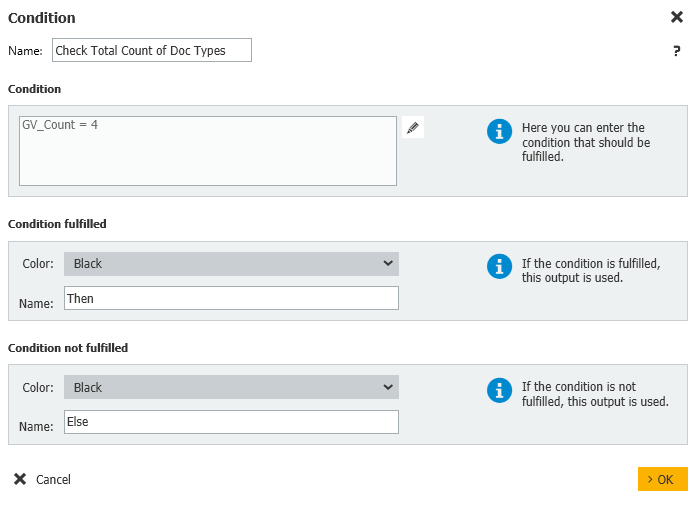
6.A continuación, comprobaremos si el tipo de documento Certificado de nacimiento se encuentra en nuestra lista recuperada de tipos de documentos para este alumno. Si se encuentra, pasamos al siguiente tipo de documento; de lo contrario, añadimos el tipo de documento al campo de índice "Missing Docs" y procedemos a un paso de Asignación de datos. Después de ejecutar el flujo de trabajo, puede comprobar este campo para todos los documentos que faltan en el registro de datos.
La siguiente información muestra cómo se configuran estos dos pasos para cada tipo de documento.
Condición: GV_Contains like "%Birth Certificate%"
Condición cumplida: Entonces
Condición no cumplida: Else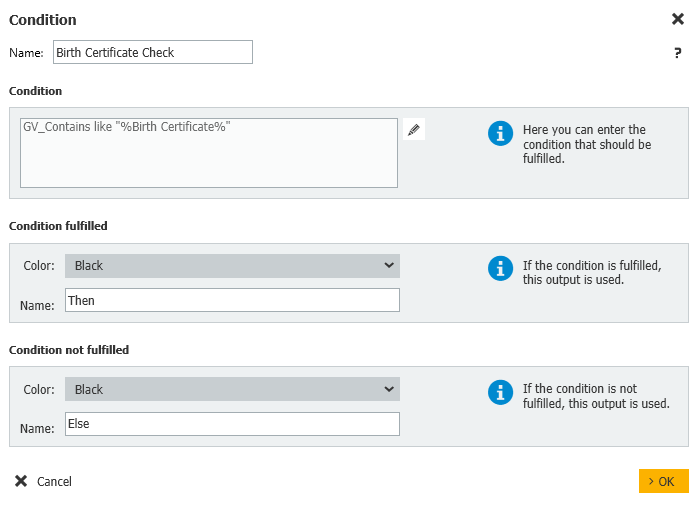
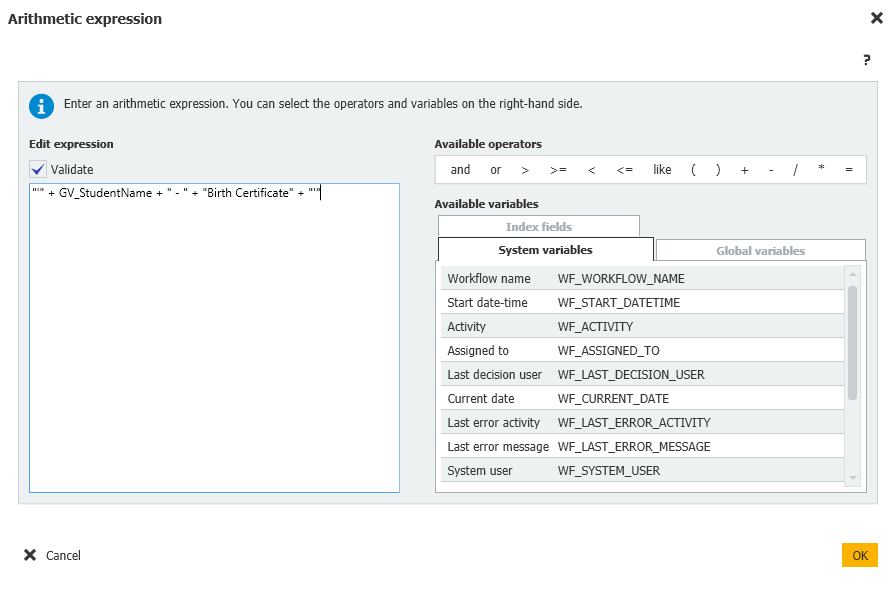
Datos de índice del documento = Faltan Docs = Expresión aritmética = "" + GV_StudentName + " - " + "Birth Certificate" + ""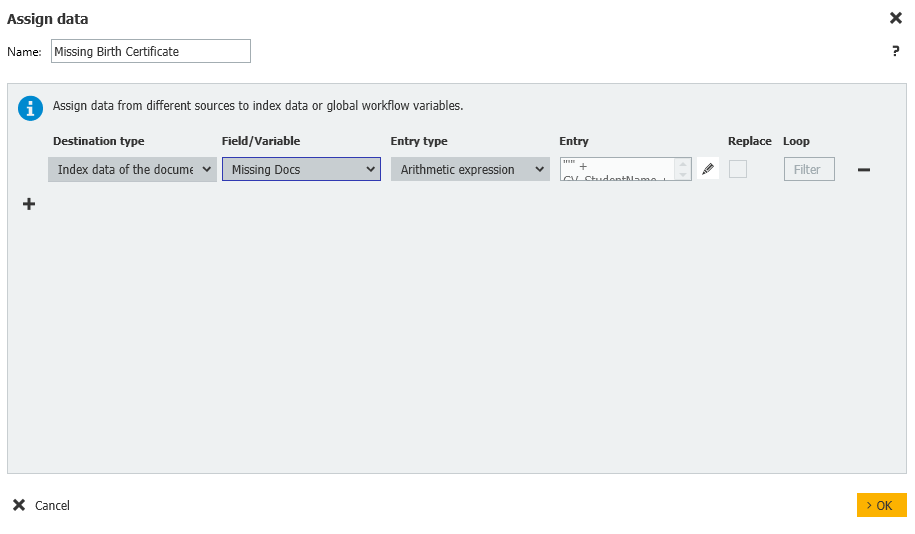
7. Esta configuración se repite para los demás documentos. Esta configuración se repite para el resto de tipos de documentos. Una vez comprobados todos los tipos de documento, todo lo que falte se añadirá a nuestro campo de palabra clave Missing Docs, y a continuación se saldrá al paso de Condición llamado "Finalizar el bucle o no".
Esta Condición comprobará si todavía hay estudiantes que necesitan ser procesados o no.
Condición: GV_Contador + 1 < COUNT(GV_StudentList)
Condición cumplida: Entonces
Condición no cumplida: Else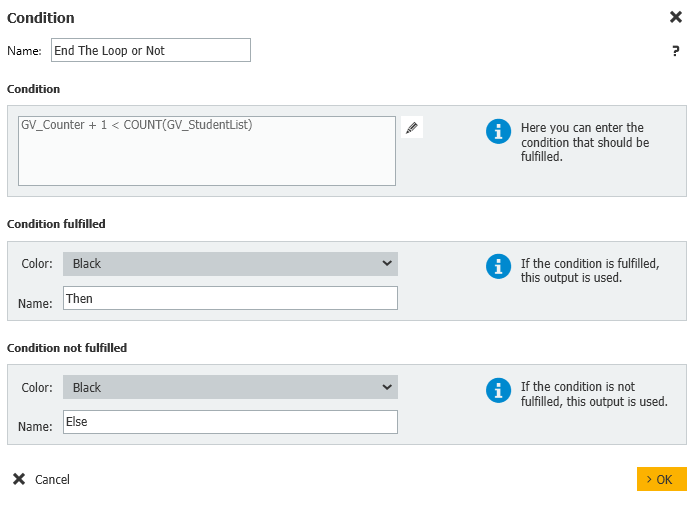
8. Si no queda ninguno, saldremos del flujo de trabajo. De lo contrario, pasaremos a un paso de Asignación de datos en el que añadiremos uno a nuestra variable contador y, a continuación, repetiremos el flujo de trabajo, comprobando si faltan documentos para el siguiente estudiante.
Workflow global variable = DocTypes = Fixed entry = NULL
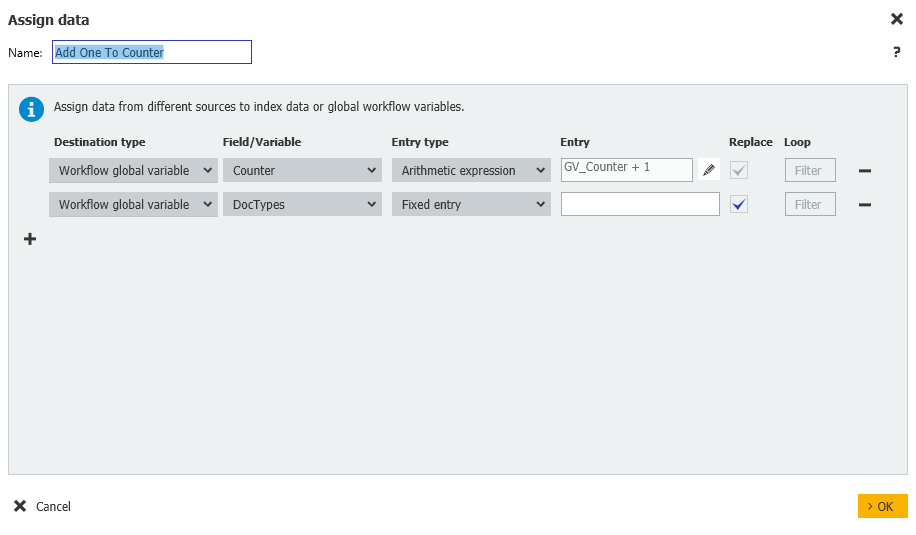
Observe que también borramos la variable global DocTypes ya que necesitaremos una pizarra limpia para procesar al siguiente usuario.
Una vez guardado y publicado este flujo de trabajo, se procederá de la siguiente manera;
- Almacenar un registro de datos en el archivador Archivos de Estudiante. (Sólo es necesario hacerlo una vez)
- Una vez almacenado, abra el registro de datos, introduzca "Activar" en el campo Estado para activar manualmente el flujo de trabajo, y cierre el registro de datos.
- Transcurridos unos instantes, cuando abra el registro de datos, el campo Documentos que faltan contendrá una lista de los Estudiantes y de los documentos que les faltan.
Si alguna vez necesita volver a ejecutar este proceso en el futuro, asegúrese de borrar todas las entradas del campo Documentos faltantes y Estado, y luego repita los pasos 2 y 3.
KBA es aplicable tanto para organizaciones en la nube como locales.
Tenga en cuenta: Este artículo es una traducción del idioma inglés. La información contenida en este artículo se basa en la(s) versión(es) original(es) del producto(s) en inglés. Puede haber errores menores, como en la gramática utilizada en la versión traducida de nuestros artículos. Si bien no podemos garantizar la exactitud completa de la traducción, en la mayoría de los casos, encontrará que es lo suficientemente informativa. En caso de duda, vuelva a la versión en inglés de este artículo.