

Question :
Comment puis-je unifier les valeurs d'index reconnues par Intelligent Indexing ?
Réponse :
Le filtre de champ peut aider l'indexation intelligente à unifier les valeurs détectées. Lesdifférentes orthographes ou fautes de frappe sur le document peuvent être automatiquement corrigées par l'indexation intelligente.
Par exemple, sur le document, le nom du destinataire est "Stahlwerk München", mais l'indexation intelligente devrait reconnaître "Stahlwerke München".
- Tout d'abord, un simple fichier TXT est créé avec les orthographes correctes qui doivent être reconnues de manière uniforme. Il est important de n'insérer qu'un seul terme par ligne dans le fichier et de ne pas utiliser de séparateurs.
- Sélectionnez le plugin Intelligent Indexing dans la page Configurations, puis cliquez sur l'option Modifier le filtre de champ .
Remarque : selon la version de DocuWare, cette option peut également s'intituler " Filtre de champ Adept " .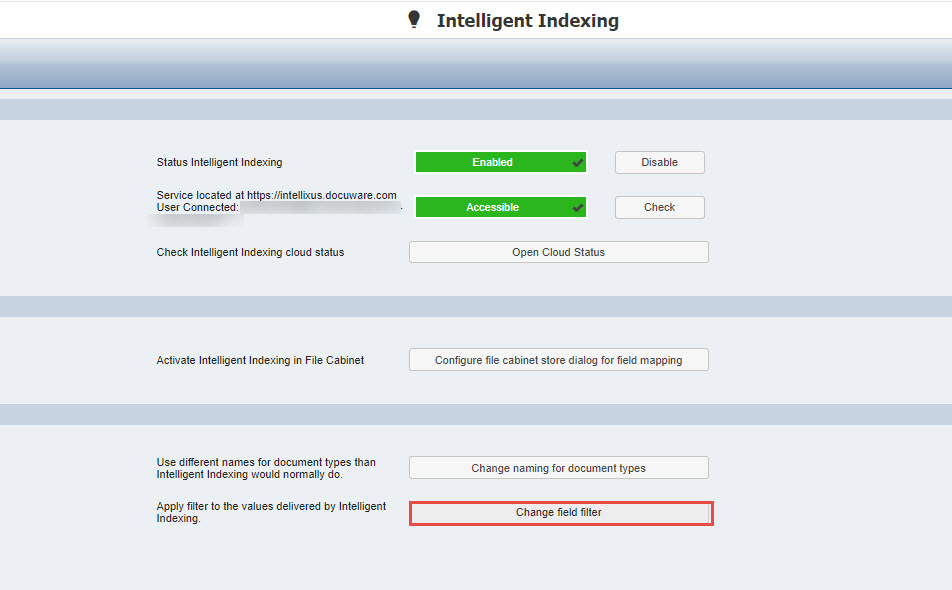
- Sélectionnez "Ajouter un nouveau filtre", téléchargez votre fichier Txt, configurez vos champs et cliquez sur Appliquer.
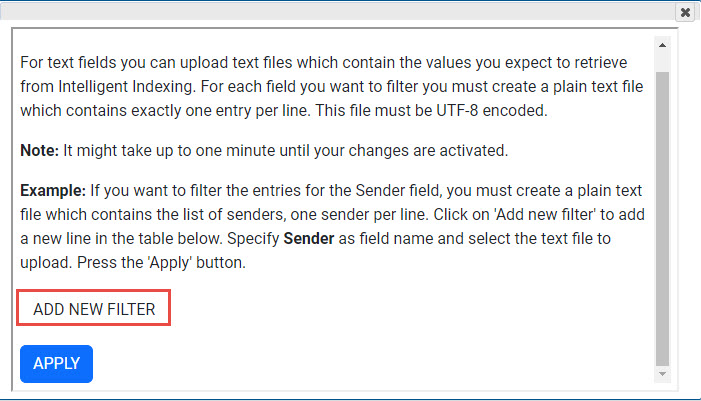
Pour tous les futurs documents traités par l'indexation intelligente, les termes d'indexation dont l'orthographe est similaire sont automatiquement adaptés au terme d'indexation stocké dans le filtre de champ.
Le KBA s'applique aussi bien aux organisations en nuage qu'aux organisations sur site.
Veuillez noter : Cet article est une traduction de l'anglais. Les informations contenues dans cet article sont basées sur la ou les versions originales des produits en langue anglaise. Il peut y avoir des erreurs mineures, notamment dans la grammaire utilisée dans la version traduite de nos articles. Bien que nous ne puissions pas garantir l'exactitude complète de la traduction, dans la plupart des cas, vous la trouverez suffisamment informative. En cas de doute, veuillez revenir à la version anglaise de cet article.