

Question:
Autoindex を使用して、ファイルキャビネットの文書数と総サイズを確認するにはどうすればよいですか?
Answer:
以下のガイドに記入して、ファイルキャビネットの文書数と総サイズを確認してください;
Autoindex を使用して、ファイルキャビネットの文書数と総サイズを確認するにはどうすればよいですか?
Answer:
以下のガイドに記入して、ファイルキャビネットの文書数と総サイズを確認してください;
1. Autoindexジョブを設定する前に、ファイルキャビネットを作成し、Autoindexプロセスが時間をかけて更新できるように、情報を保持するための一元化された場所を確保 します。ファイルキャビネットに名前を付け、以下の3つのデータベースフィールドを作成します:ファイルキャビネット名」、「 文書数」、「 FC サイズ合計」です。
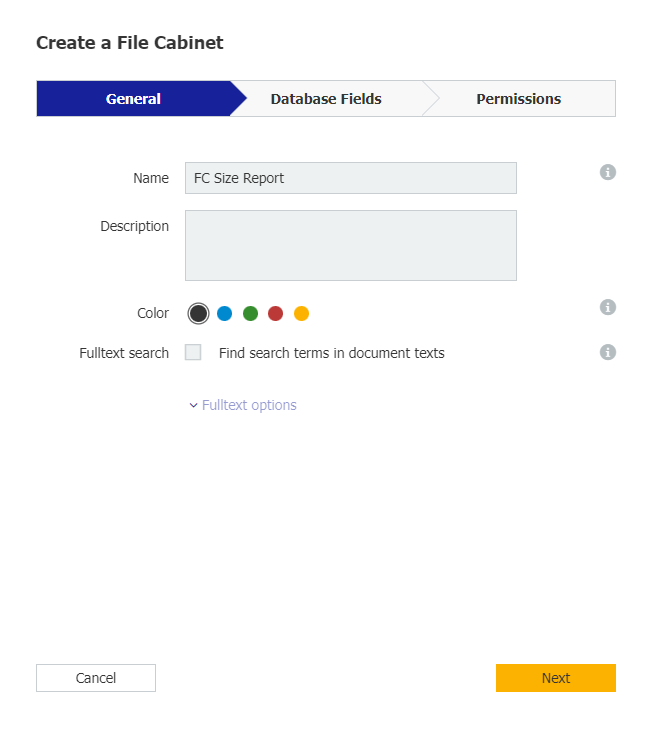
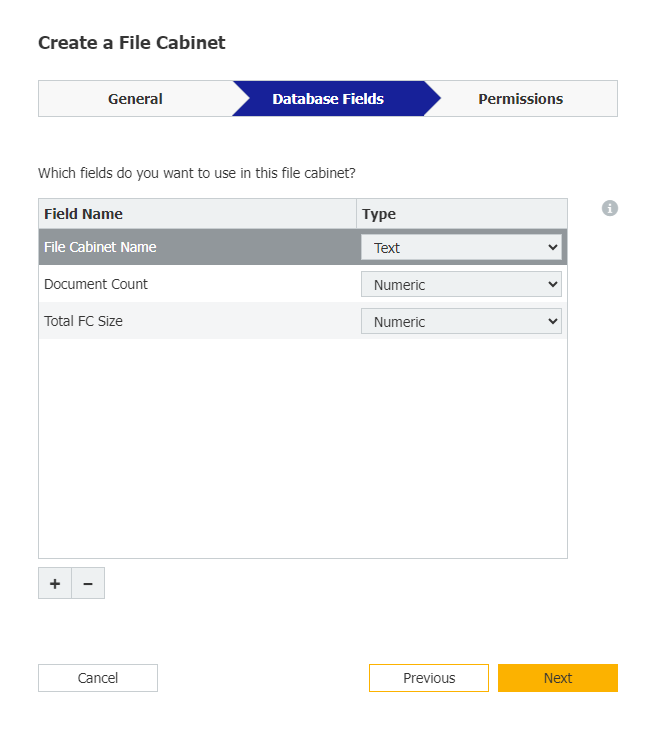
2.ファイルキャビネットを作成したら、Autoindexジョブを作成します。Add data in"セクションから新しく作成したファイルキャビネットを選択し、トリガー条件の残りの部分が以下と一致していることを確認します;
2.ファイルキャビネットを作成したら、Autoindexジョブを作成します。Add data in"セクションから新しく作成したファイルキャビネットを選択し、トリガー条件の残りの部分が以下と一致していることを確認します;
スケジュールされた
フィルタ = DOCID = Is not equal = 0
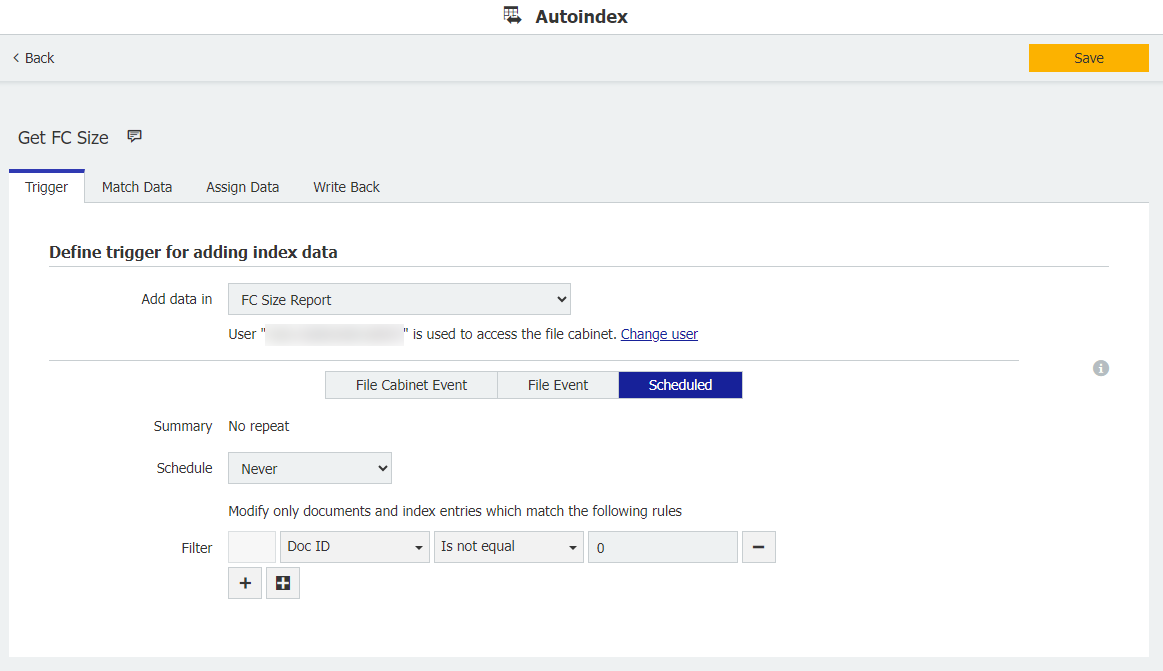
フィルタ = DOCID = Is not equal = 0
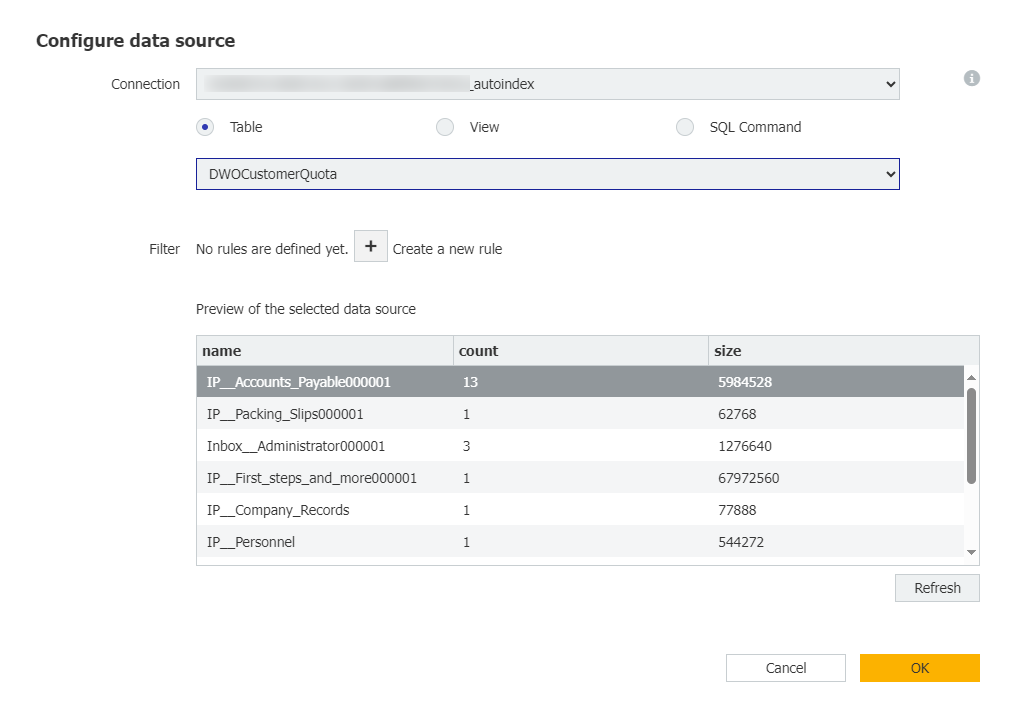
3. MatchDataタブで 外部データベースを 有効にし、configure data sourceを 選択する。autoindex"で終わる接続を選択し、 DWOCustomerQuotaテーブルを開く。このテーブルを選択すると、システム内に存在するすべてのファイルキャビネットと、ファイルキャビネットの文書数とサイズが表示されます。この情報が表示されたら、[OK]をクリックします。
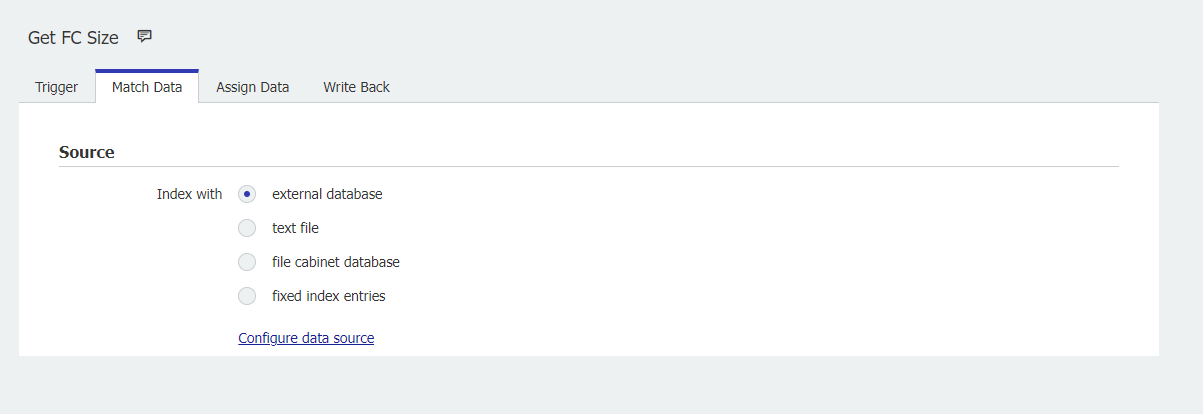
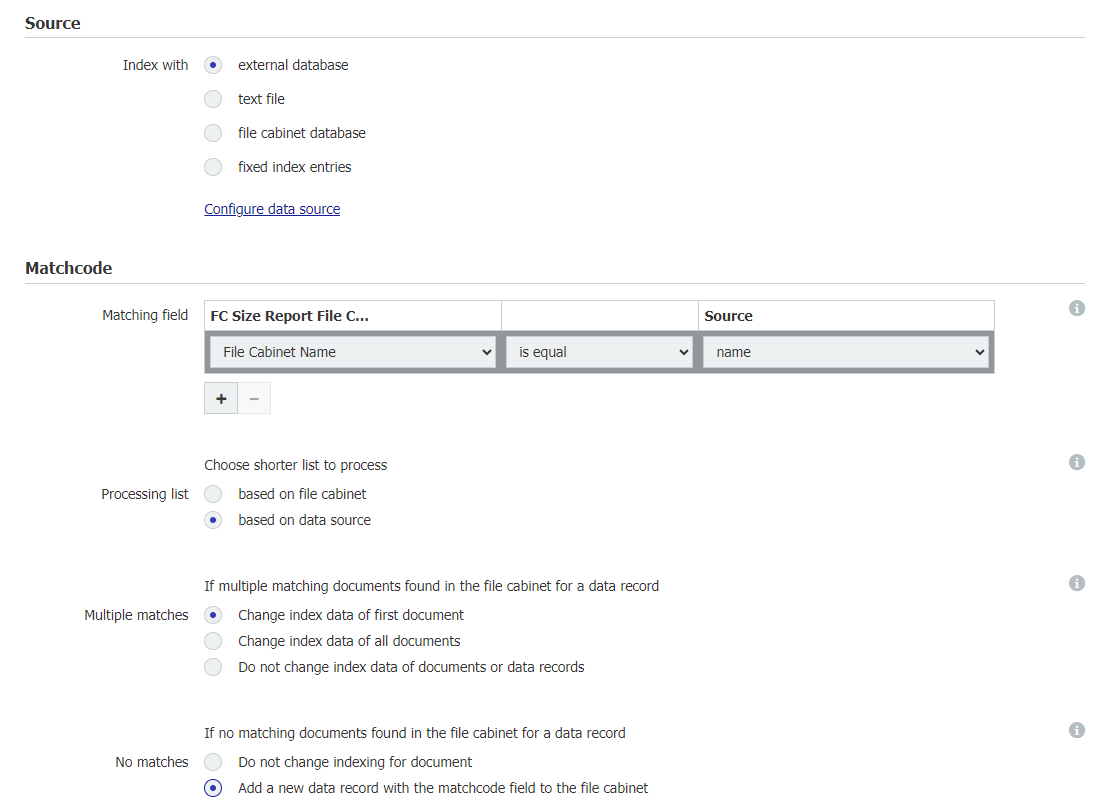
4.データ・ソースが構成されたので、Matchcode セクションを完成させ、以下を反映させる;
Matchcode
マッチング・フィールド:File Cabinet Name = is equal = name
Processing list = based on data source
Multiple matches = Change index data of first document
No matches = Add a new record with the matchcode field to the file cabinet.
マッチング・フィールド:File Cabinet Name = is equal = name
Processing list = based on data source
Multiple matches = Change index data of first document
No matches = Add a new record with the matchcode field to the file cabinet.
5.
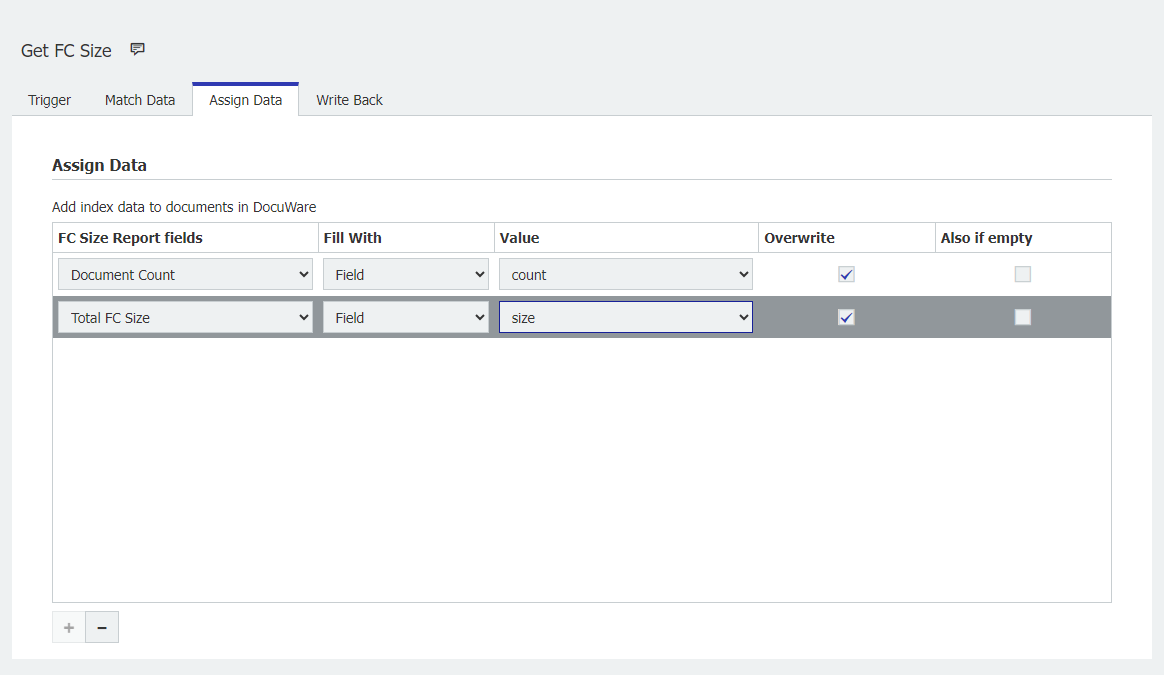
Assign Data
Document Count = Field = count = Overwrite:有効
FC合計サイズ = フィールド = サイズ = 上書き:有効
6.Write Back"タブのすべての設定は、デフォルト・オプションのままでよい。設定を保存すると、ジョブの実行時にデータレコードをCSVファイルにダウンロードできるようになります。
これはスケジュールで実行されるため、時間の経過とともにデータレコードのサイズが変化しても更新され続けます。
Assign Data
Document Count = Field = count = Overwrite:有効
FC合計サイズ = フィールド = サイズ = 上書き:有効
6.Write Back"タブのすべての設定は、デフォルト・オプションのままでよい。設定を保存すると、ジョブの実行時にデータレコードをCSVファイルにダウンロードできるようになります。
これはスケジュールで実行されるため、時間の経過とともにデータレコードのサイズが変化しても更新され続けます。
KBAはクラウド 組織のみに適用されます。
ご注意:この記事は英語からの翻訳です。この記事に含まれる情報は、オリジナルの英語版製品に基づくものです。翻訳版の記事で使用されている文法などには、細かい誤りがある場合があります。翻訳の正確さを完全に保証することは出来かねますが、ほとんどの場合、十分な情報が得られると思われます。万が一、疑問が生じた場合は、英語版の記事に切り替えてご覧ください。