

Question:
How can you setup a process which will flag duplicate documents, which are already stored in a file cabinet?
Answer:
In order to setup this kind of process, this can be done using AutoIndex and Workflow. Please refer to the configurations below for an example setup.
In our scenario, let's say we have documents stored in our file cabinet, and there are documents using the same "Original DocID" like shown below;
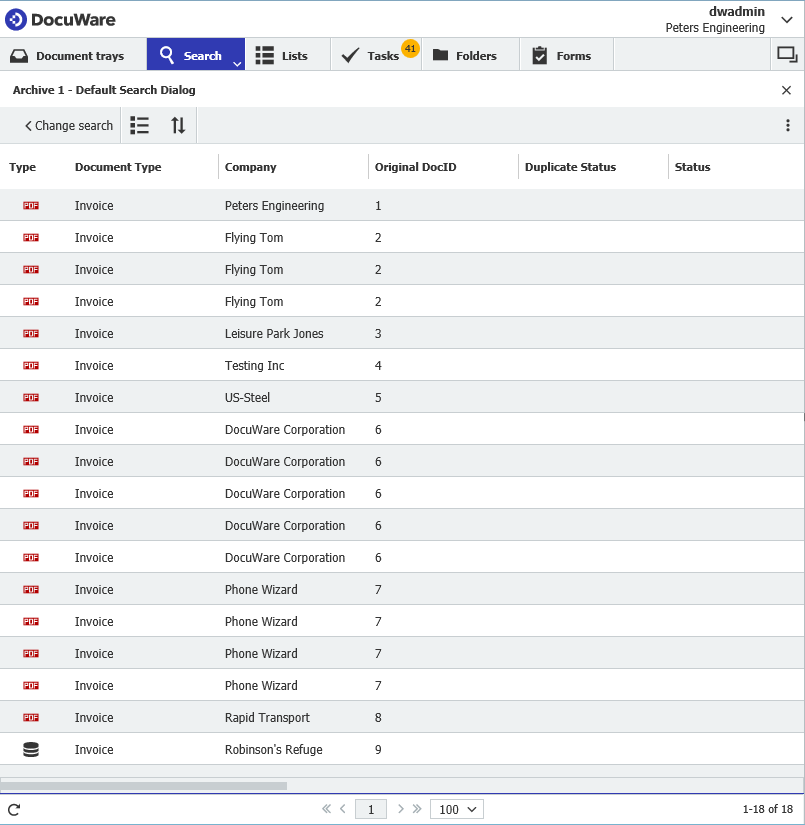
(Note: For purposes of this exercise, it's recommended to create the following text data type index field "Duplicate Status")
The first phase is performing a search of the file cabinet to find the first instance of a unique value which would normally indicate that there's a duplicate.
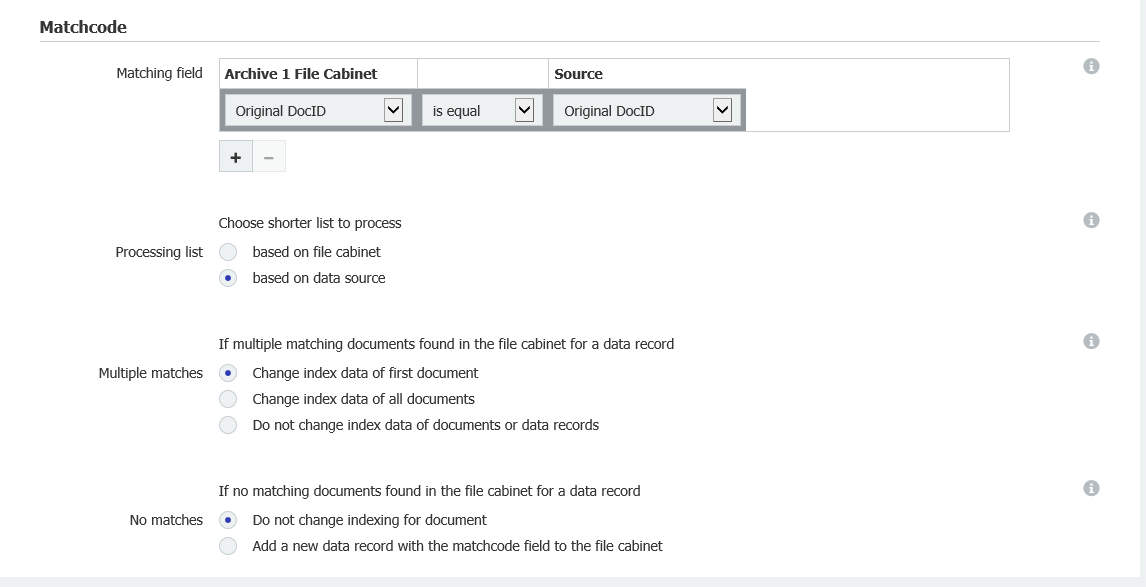
For this example, we'll be using "Original DocID", where we'll be checking documents where the same Original DocID is used.
To do this, we require an AutoIndex job is created, which uses the following configuration,
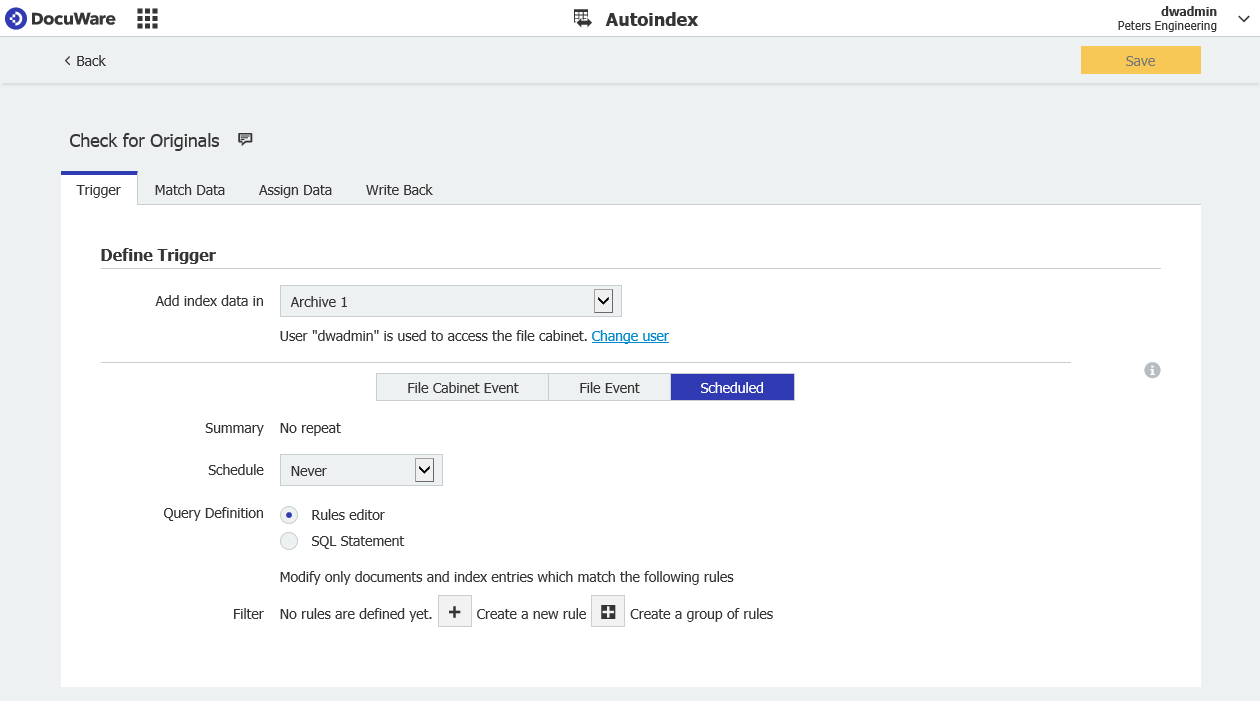
- We'll start by creating a Scheduled AutoIndex job as shown below.
- From the Match Data section, select "File Cabinet database" for the source, then choose the name of the file cabinet you wish to monitor.
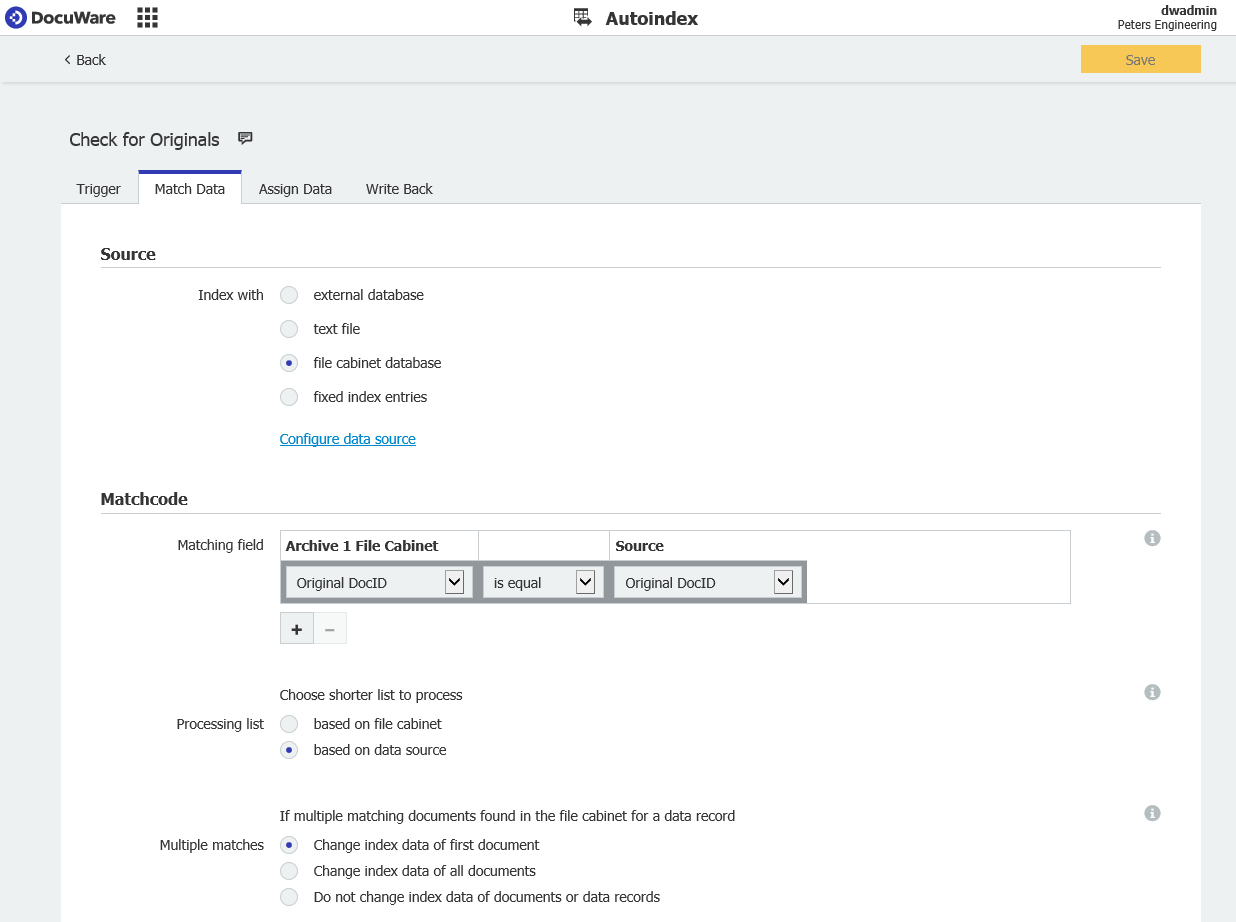
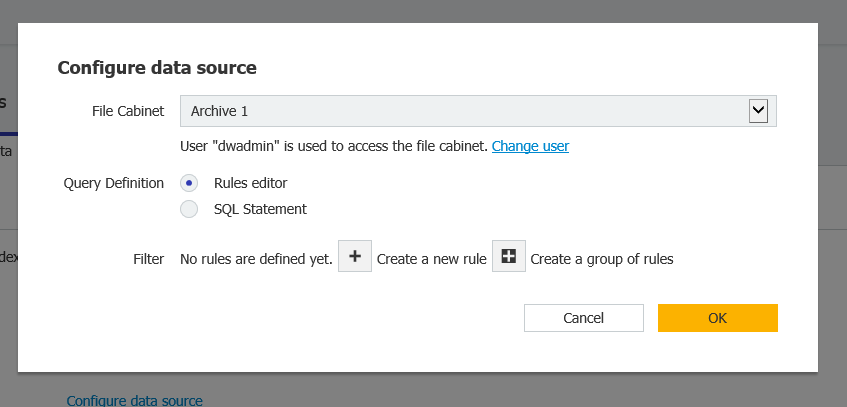
In the Matchcode section, select "based on data source" from "Processing list" and "Change index data of first document" from "Multiple Searches"
This will ensure that in the case we encounter multiple matches of the same value, that we only update the first one and mark it as the original.
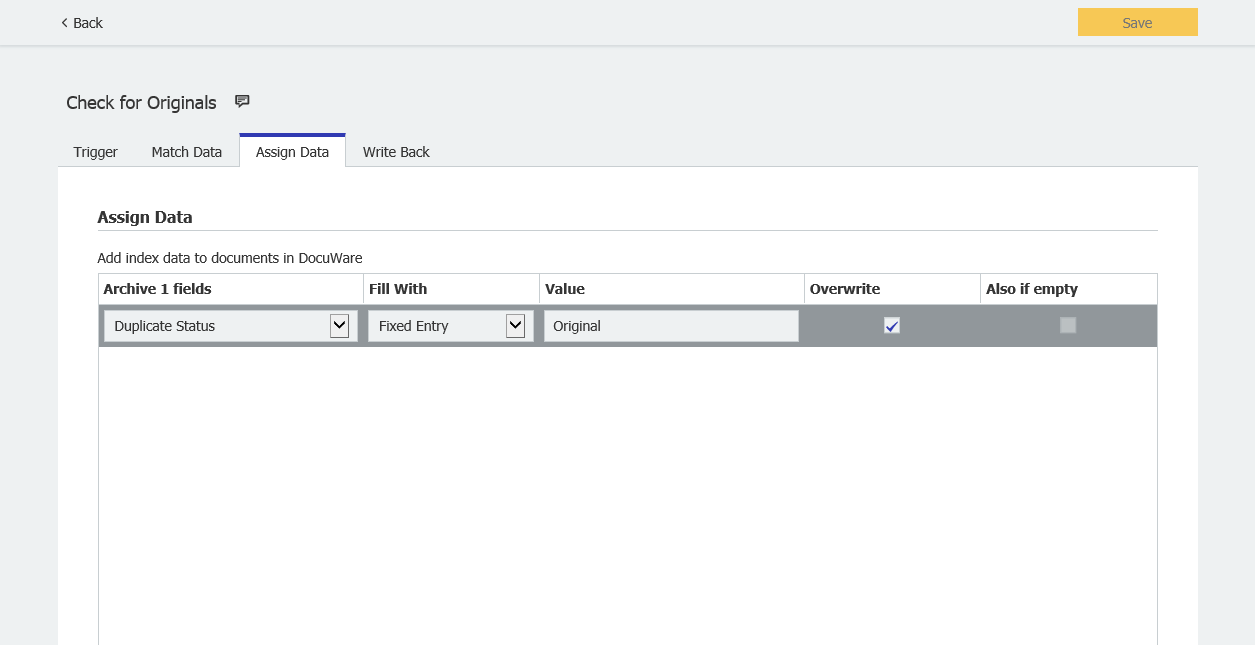
- In Assign Data, update the Duplicate Status as "Original."
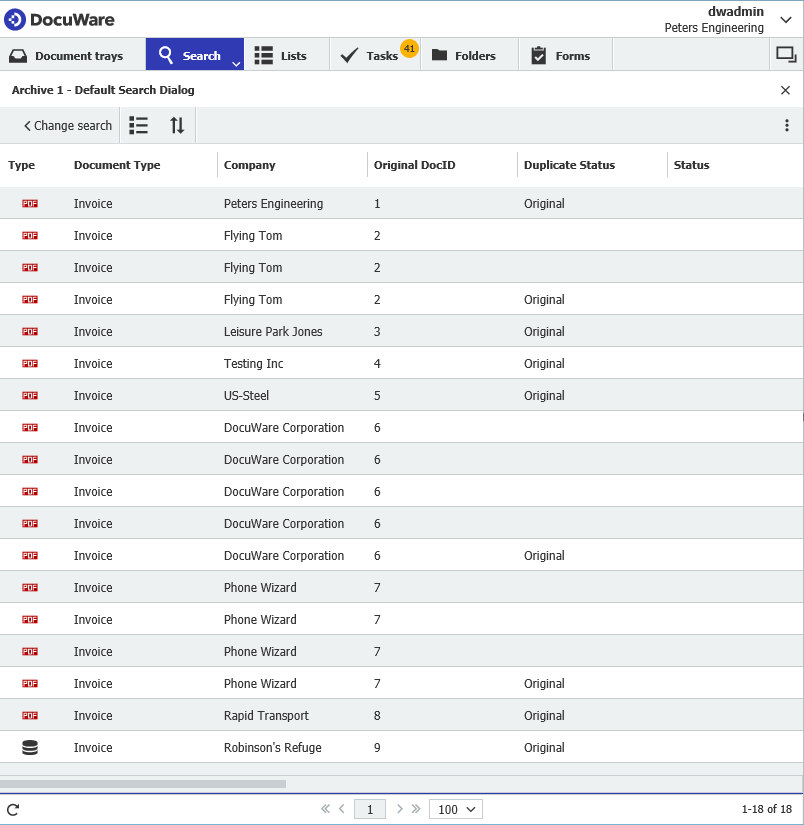
- Save your changes then manually run the AutoIndex job. Once ran, we should see that the first instance of any Original DocID found will be updated with Original and all duplicates have been skipped as shown below. We can proceed to the setup of the workflow.
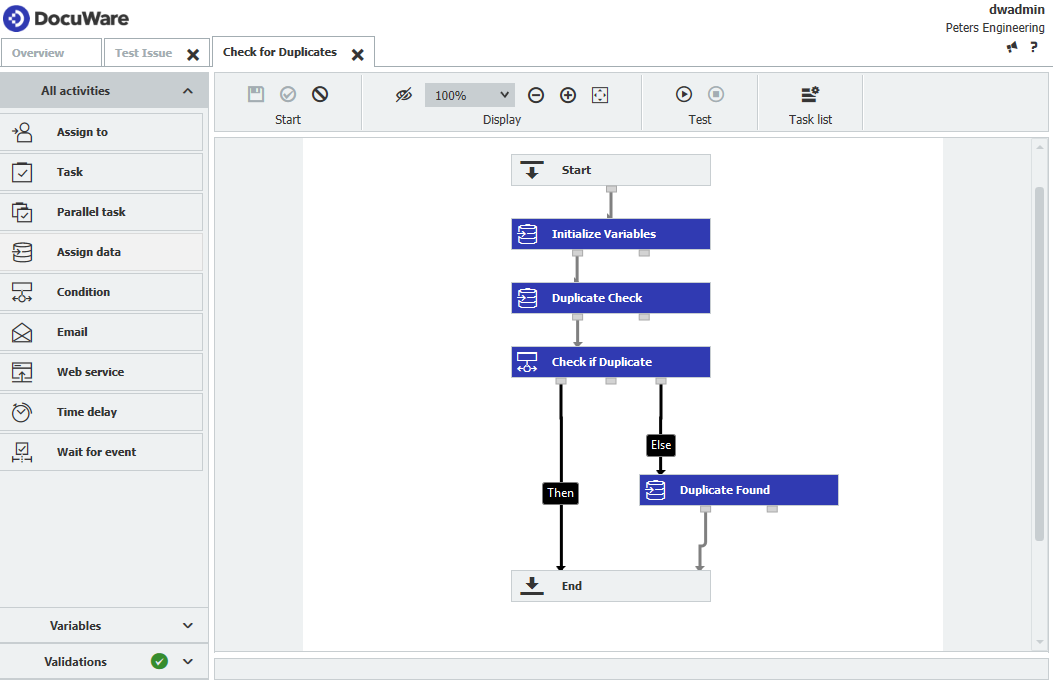
With the Original's flagged, the next phase is using Workflow to flag the duplicate entries. A workflow configured to accomplish this is as follows,
- An overview of the workflow that will be created will look like the following,
- The variables below will need to be created for this workflow.
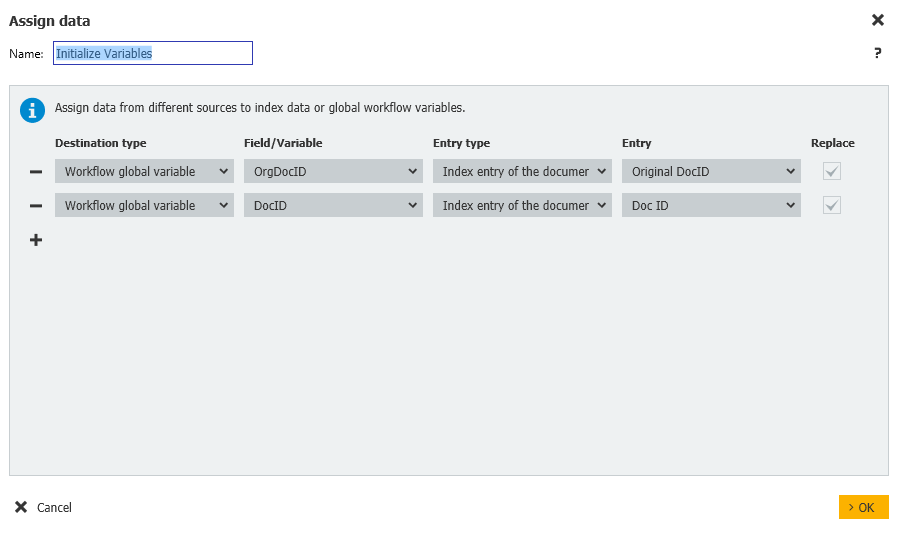
- In our Assign Data step, the OrgDocID and DocID variables are initialized and mapped to the corresponding file cabinet index fields.
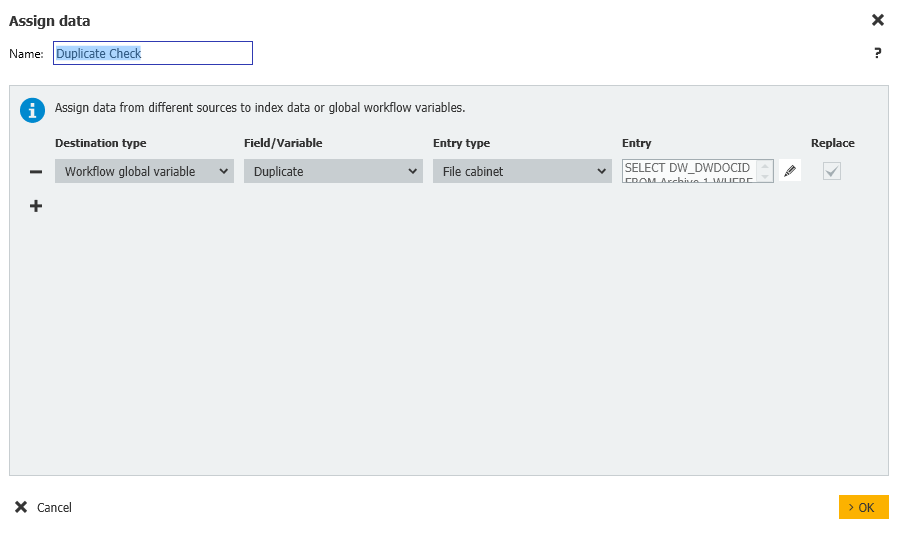
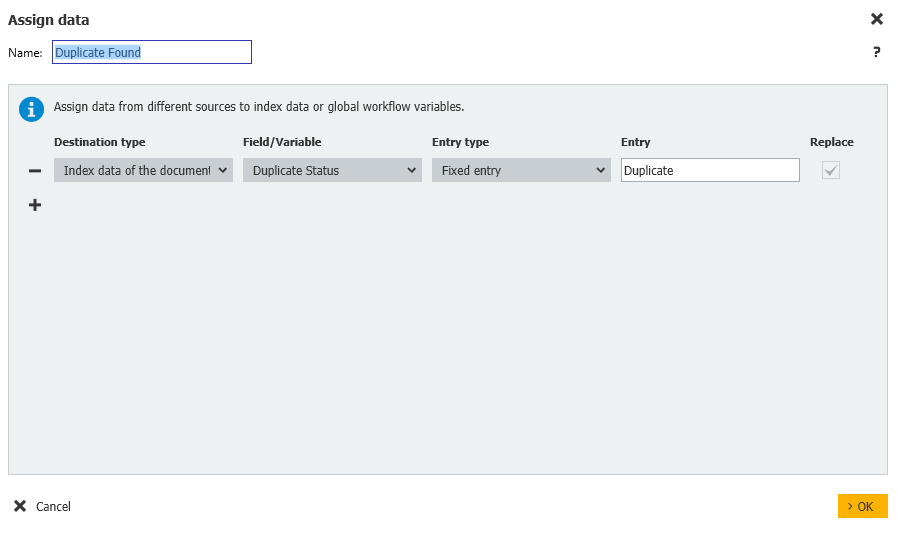
- Next, another Assign Data step is created where the Duplicate variable is initialized and we'll be using a File Cabinet lookup in order to see if there are any duplicates to flag.
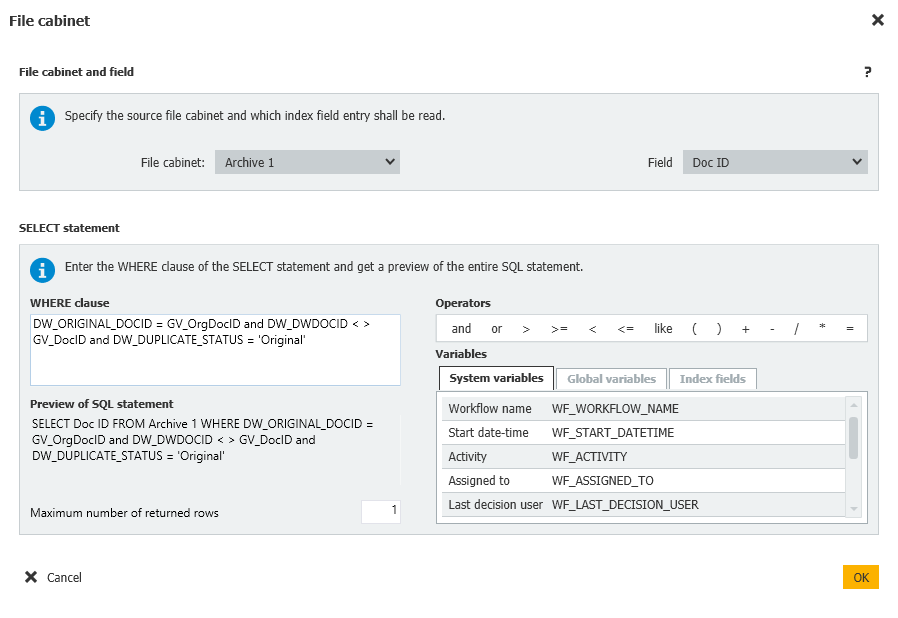
The Select statement in this case will be checking if there are other entries in the file cabinet containing the same Original DocID as the document currently in the workflow, if the DocID does not match the DocID as the one in the workflow, and finally if there's anything in the file cabinet which has been marked as the Original.
If an Original is found, then the document in the workflow will be marked as a duplicate.
- Once the file cabinet lookup has been done, the Duplicate global variable will either be empty or contains a value.
If a DocID was returned, then this indicates that a duplicate has been found. We will route it in the workflow so that the Duplicate Status can be updated accordingly.
If the global variable is empty, then we'll exit the workflow as nothing further is needed.
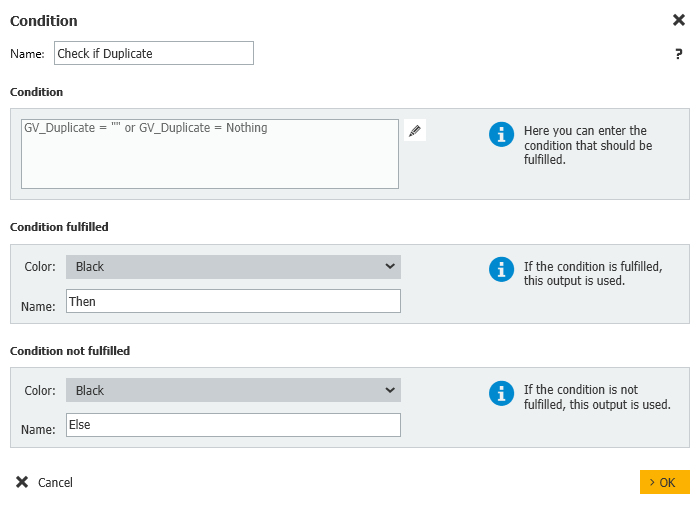
- If a duplicate was found, then we'll update the Duplicate Status field to Duplicate.
Once completed, we can trigger the workflow for all documents in the file cabinet. The workflow will determine which is a duplicate and which isn't, then update the Duplicate Status accordingly. After running this, the results will look like the following;
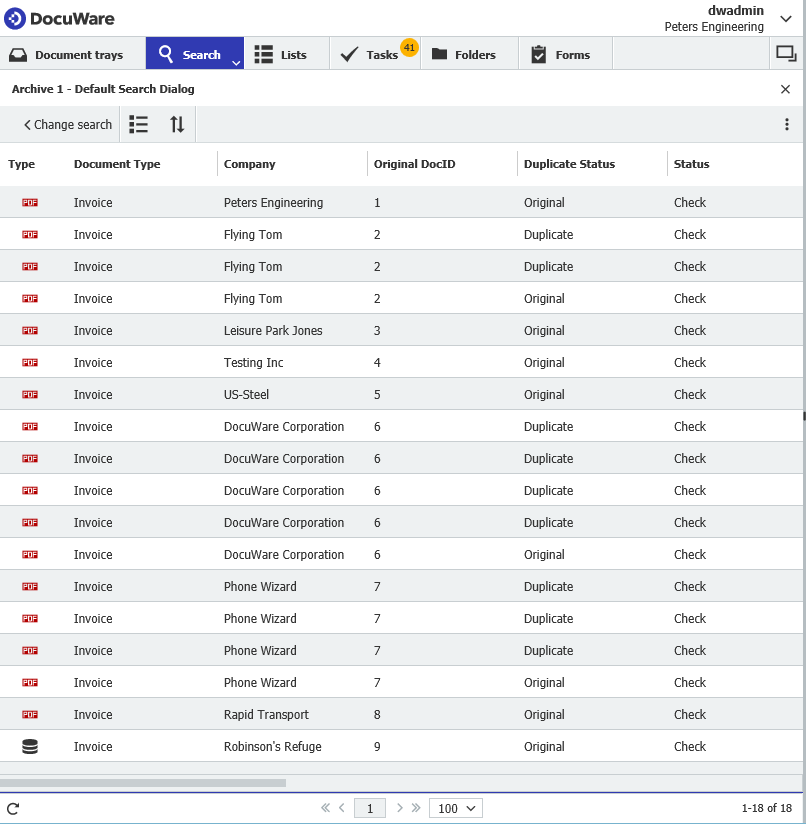
Once all duplicates have been identified, you'll be in a better position to handle these, such as using a deletion policy. More on setting this up can be found here. KBA-36331 · DocuWare Support Portal
KBA applicable for both Cloud and On-premise Organizations.