

Question:
ファイルキャビネットに保管されている重複文書にフラグを立てるプロセスを設定する方法を教えてください。
Answer:
この種のプロセスを設定するには、AutoIndex と Workflowを使用します。
このシナリオでは、ファイルキャビネットに保存された文書があり、下図のように同じ "Original DocID "を使用する文書があるとします。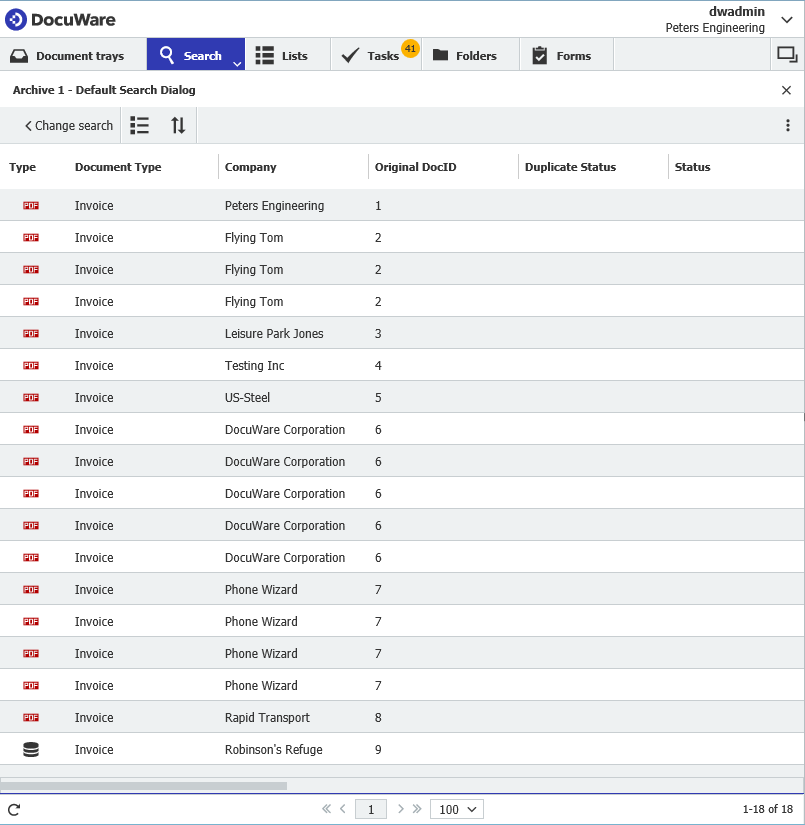
(注:この演習では、以下のテキストデータ型のインデックスフィールド "Duplicate Status "を作成することを推奨します)
最初のフェーズでは、ファイルキャビネットの検索を実行し、通常は重複があることを示す一意の値の最初のインスタンスを見つけます。
この例では、"Original DocID "を使用します。ここでは、同じOriginal DocIDが使用されている文書をチェックします。
これを行うには、以下の構成を使用するAutoIndexジョブを作成する必要があります、
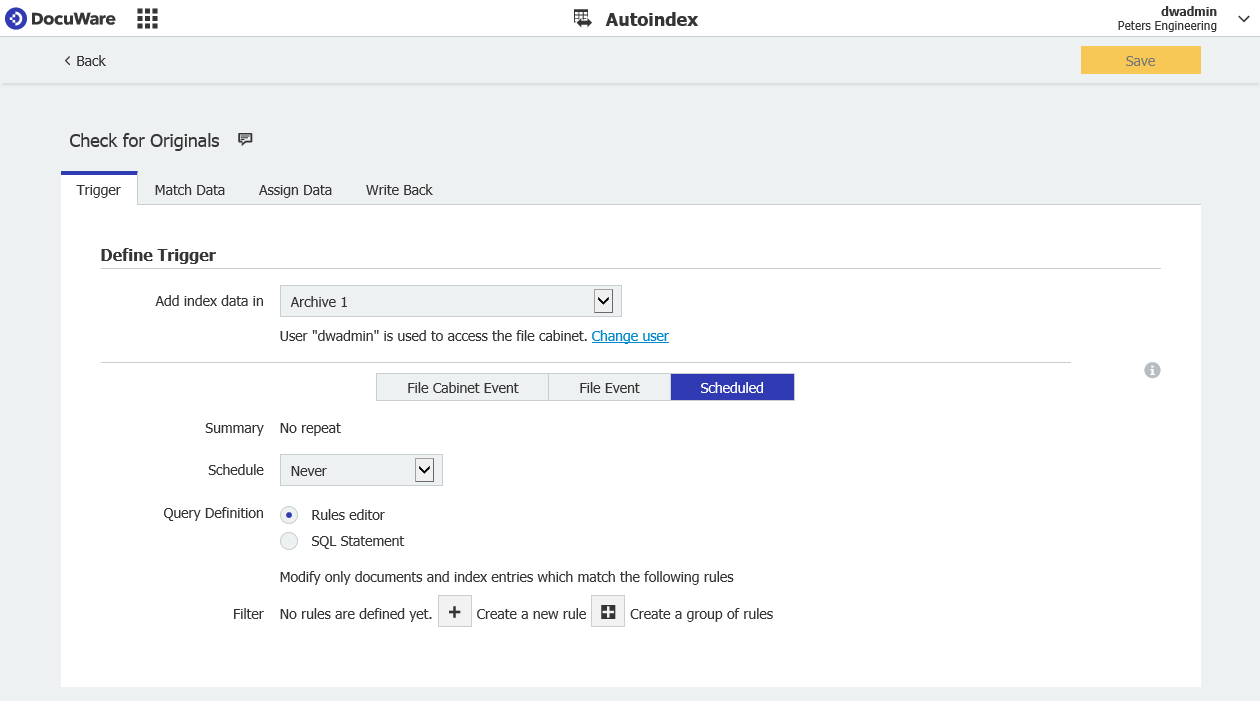
- まず、以下のようにスケジュールされた AutoIndex ジョブを作成します。
- Match Dataセクションで、ソースに"File Cabinet database"を選択し、監視したいファイル・キャビネットの名前を選択する。
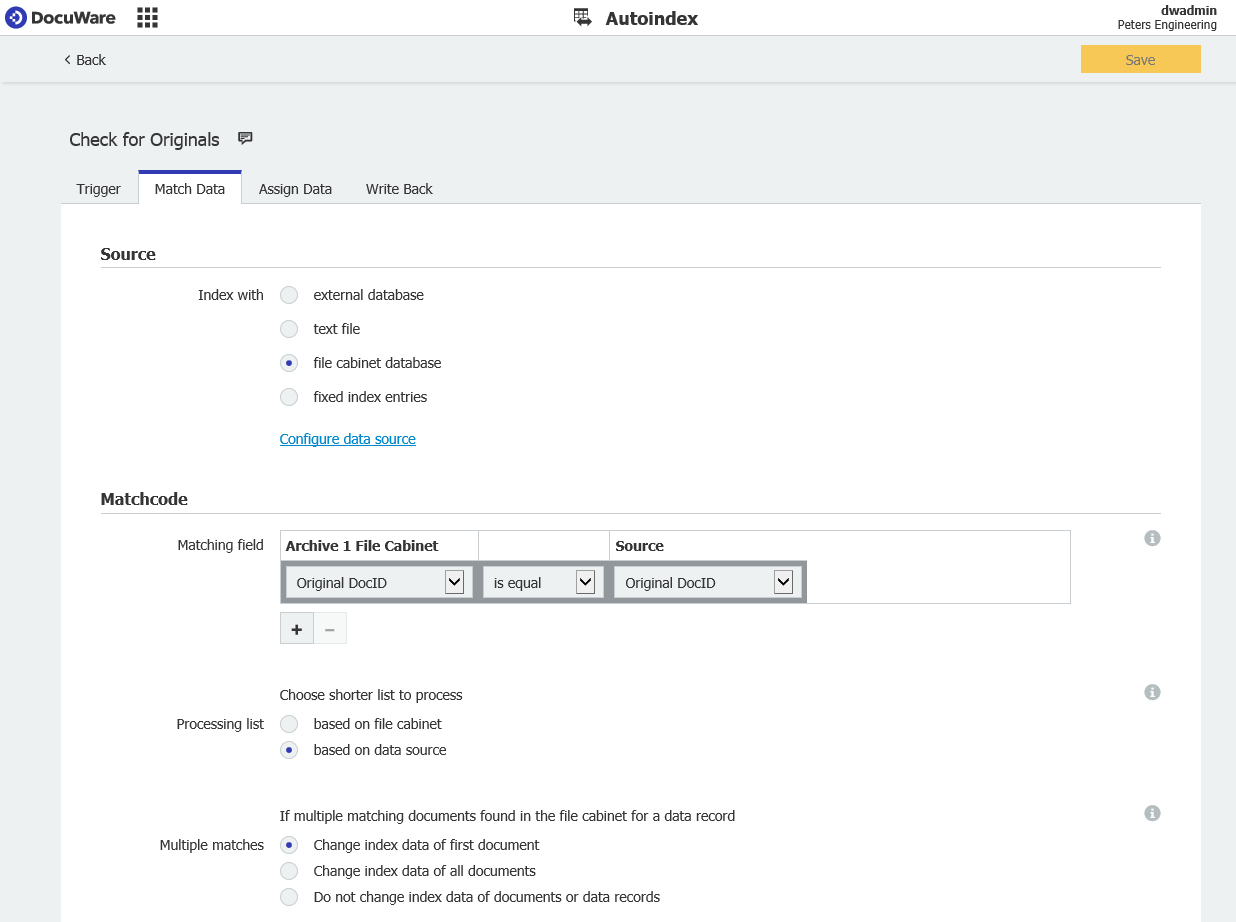
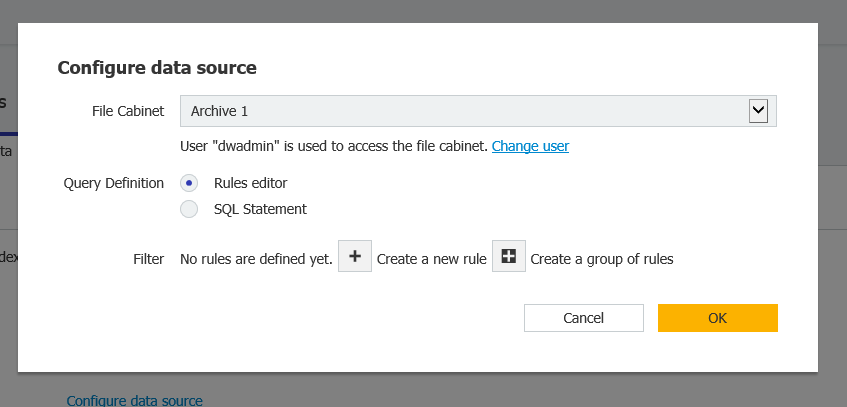
Matchcodeセクションで、"Processing list "から"based on data source"を選択し、"Multiple Searches "から"Change index data of first document"を選択します。
これにより、同じ値が複数一致した場合、最初のものだけを更新し、オリジナルとしてマークすることができます。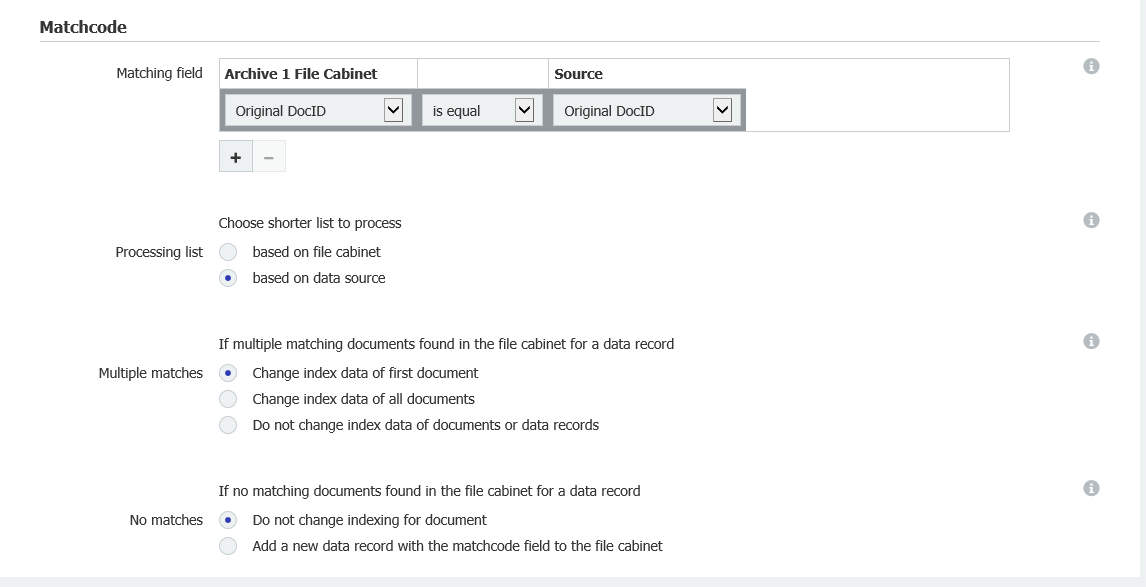
- Assign Dataで、Duplicate Statusを"Original"に更新する。
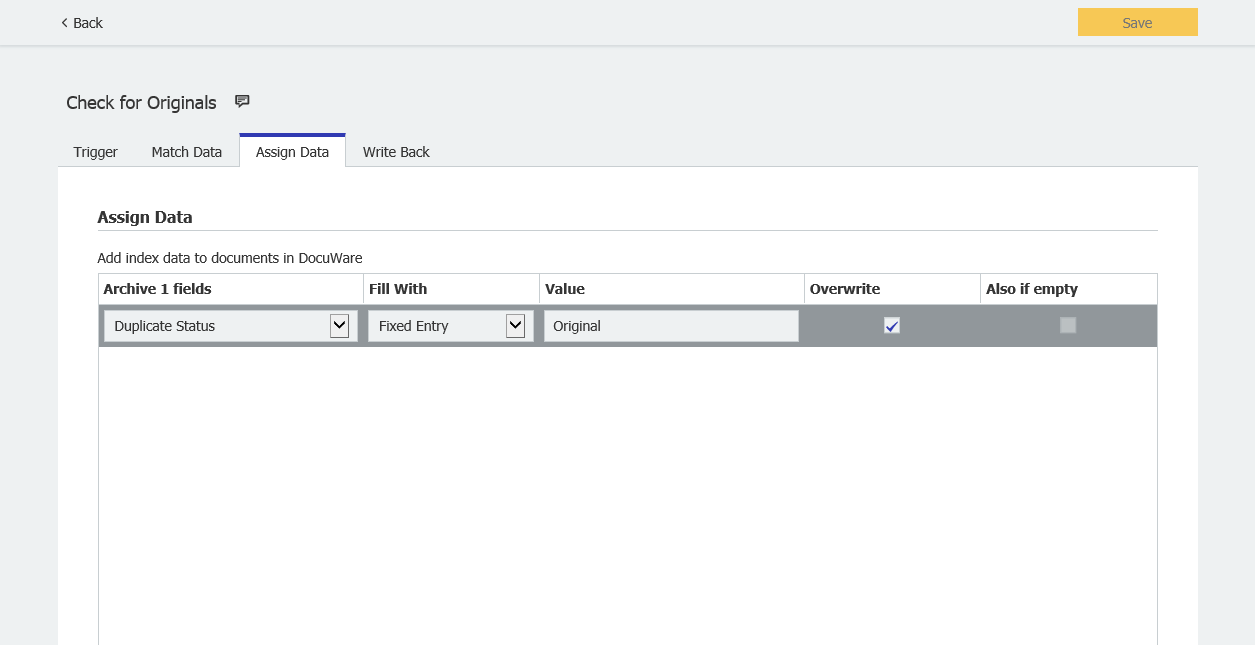
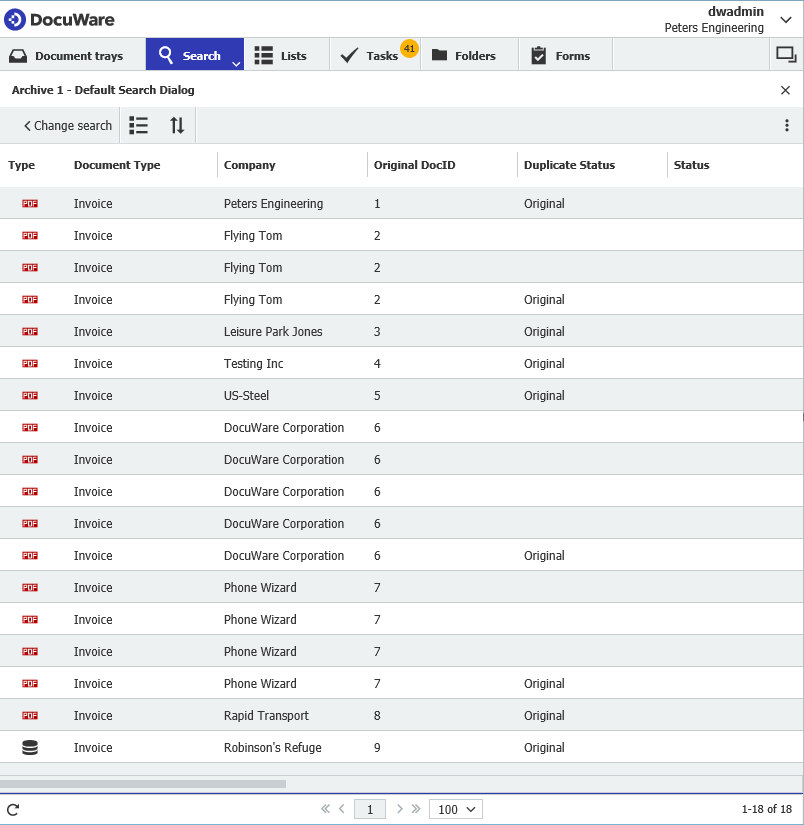
- 変更を保存し、AutoIndex ジョブを手動で実行します。実行すると、下図のように、最初に見つかったOriginal DocIDのインスタンスがOriginalに更新され、すべての重複がスキップされていることが確認できるはずです。ワークフローのセットアップに進むことができる。
Originalのフラグが立ったので、次の段階ではワークフローを使って重複エントリにフラグを立てる。そのためのワークフローは以下の通りである、
- 作成されるワークフローの概要は以下のようになる、
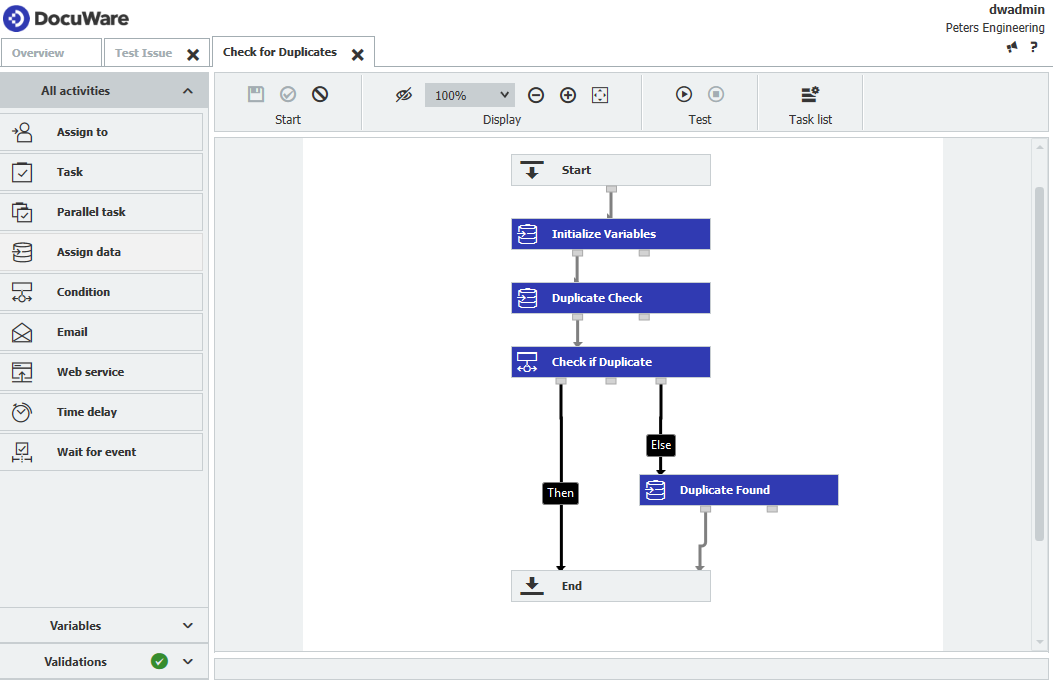
- このワークフローでは、以下の変数を作成する必要がある。
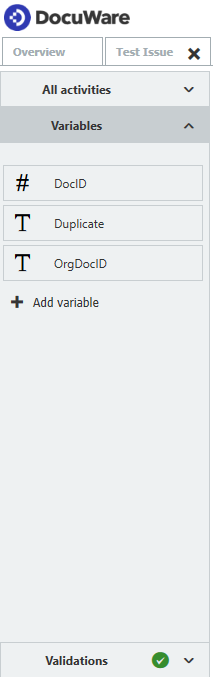
- Assign Dataステップで、OrgDocIDとDocID変数が初期化され、対応するファイル・キャビネット・インデックス・フィールドにマッピングされます。
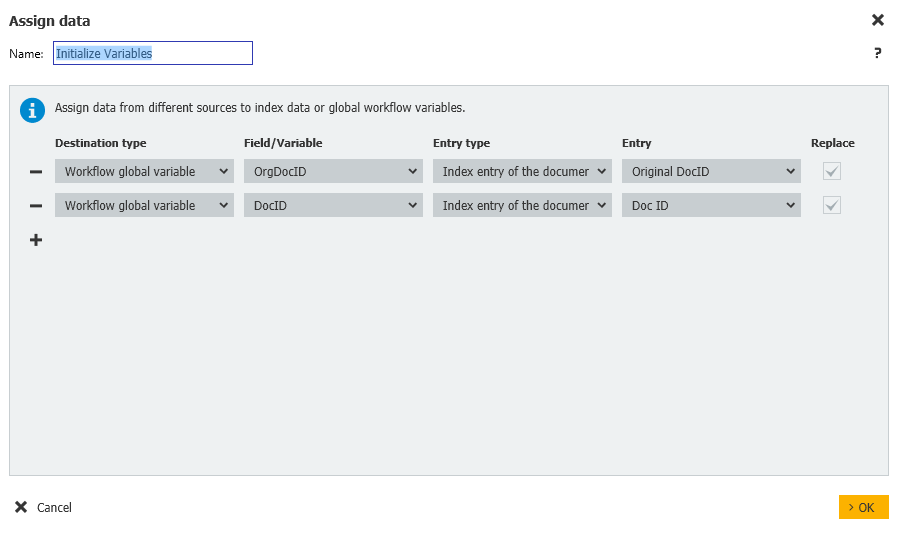
- 次に、別のデータ割り当てステップが作成され、Duplicate変数が初期化され、フラグを立てる重複があるかどうかを確認するためにファイルキャビネット検索を使用します。
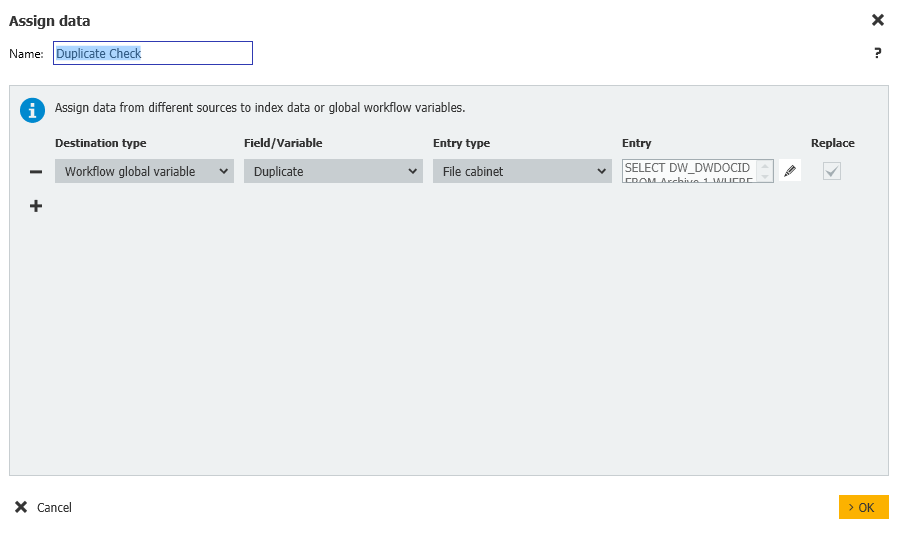
この場合のSelect文は、現在ワークフロー内のドキュメントと同じOriginal DocIDを含むエントリがファイルキャビネット内にあるかどうか、DocIDがワークフロー内のドキュメントと一致しないかどうか、そして最後にファイルキャビネット内にOriginalとしてマークされたものがあるかどうかをチェックします。
Originalが見つかった場合、ワークフロー内のドキュメントは複製としてマークされます。
- ファイルキャビネットの検索が行われると、Duplicateグローバル変数は空か値を含みます。
DocIDが返された場合、これは複製が見つかったことを示します。 Duplicate Statusがそれに応じて更新されるように、ワークフローでそれをルーティングします。
グローバル変数が空の場合、これ以上何も必要ないのでワークフローを終了します。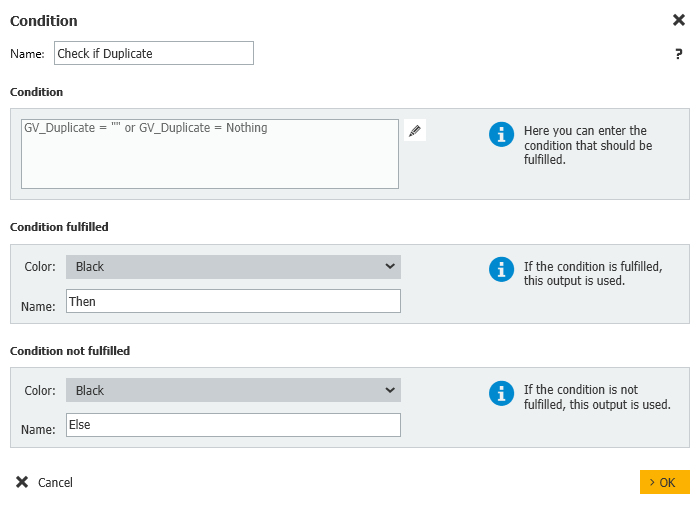
- 重複が見つかった場合、Duplicate Status フィールドを Duplicate に更新する。
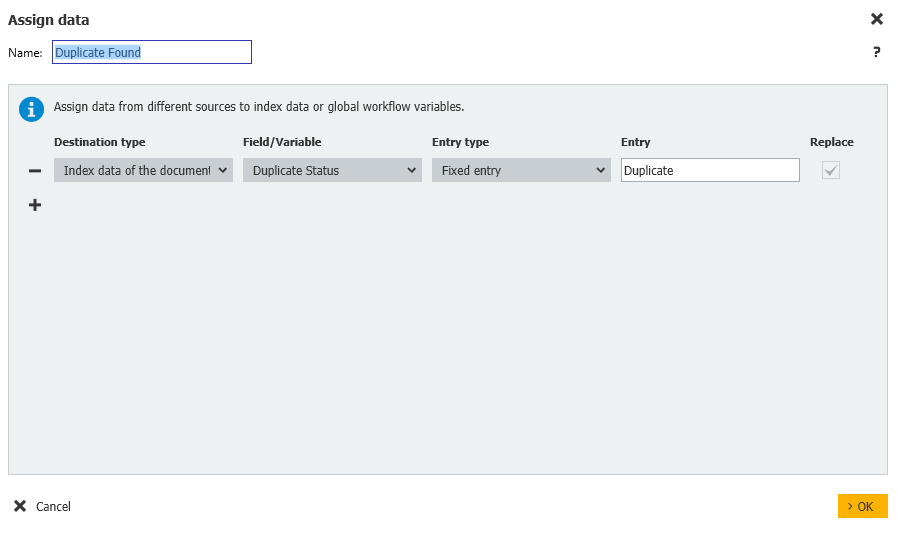
ワークフローはどれが重複でどれが重複でないかを判断し、それに応じてDuplicate Statusを更新します。これを実行すると、結果は次のようになります。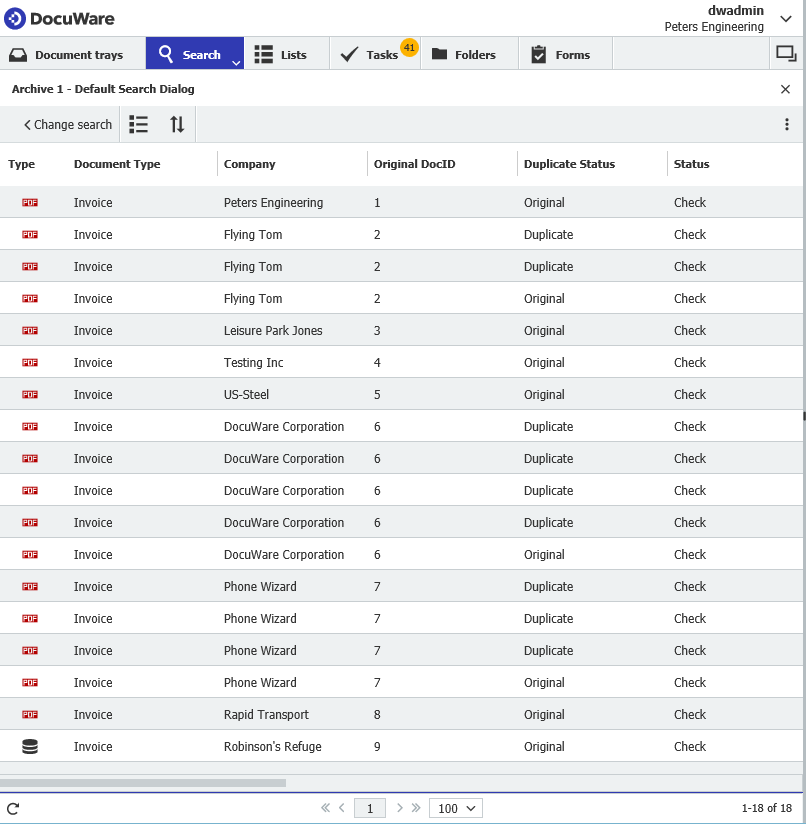
すべての重複が特定されると、削除ポリシーを使用するなど、重複を処理しやすくなります。 この設定の詳細については、こちらを参照してください。KBA-36331 - DocuWare Support Portal
クラウドとオンプレミスの両方の組織に適用可能なKBA。
ご注意:この記事は英語からの翻訳です。この記事に含まれる情報は、オリジナルの英語版製品に基づくものです。翻訳版の記事で使用されている文法などには、細かい誤りがある場合があります。翻訳の正確さを完全に保証することは出来かねますが、ほとんどの場合、十分な情報が得られると思われます。万が一、疑問が生じた場合は、英語版の記事に切り替えてご覧ください。