

Pregunta:
¿Cómo se puede configurar un proceso que marque los documentos duplicados que ya están almacenados en un archivador?
Respuesta:
Para configurar este tipo de proceso, se puede utilizar AutoIndex y Workflow. Consulte las configuraciones siguientes para ver un ejemplo de configuración.
En nuestro escenario, supongamos que tenemos documentos almacenados en nuestro archivador y que hay documentos que utilizan el mismo "DocID original", como se muestra a continuación;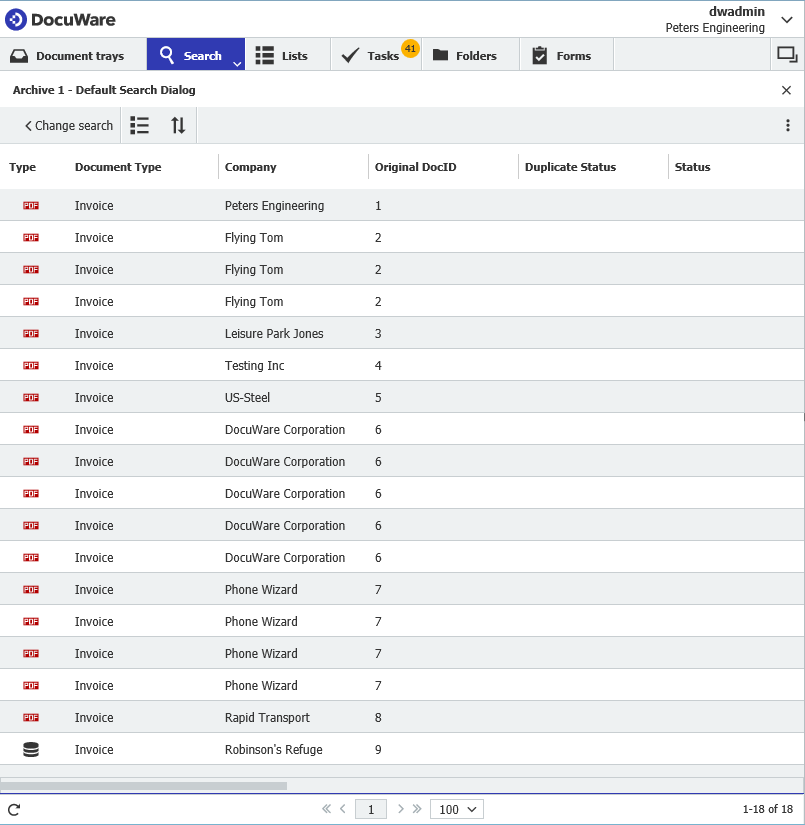
(Nota: Para los fines de este ejercicio, se recomienda crear el siguiente campo de índice de tipo de datos de texto "Estado de duplicado")
La primera fase consiste en realizar una búsqueda en el archivador para encontrar la primera instancia de un valor único que normalmente indicaría que hay un duplicado.
Para este ejemplo, utilizaremos "Original DocID", donde comprobaremos los documentos en los que se utiliza el mismo Original DocID.
Para ello, es necesario crear un trabajo AutoIndex que utilice la siguiente configuración,
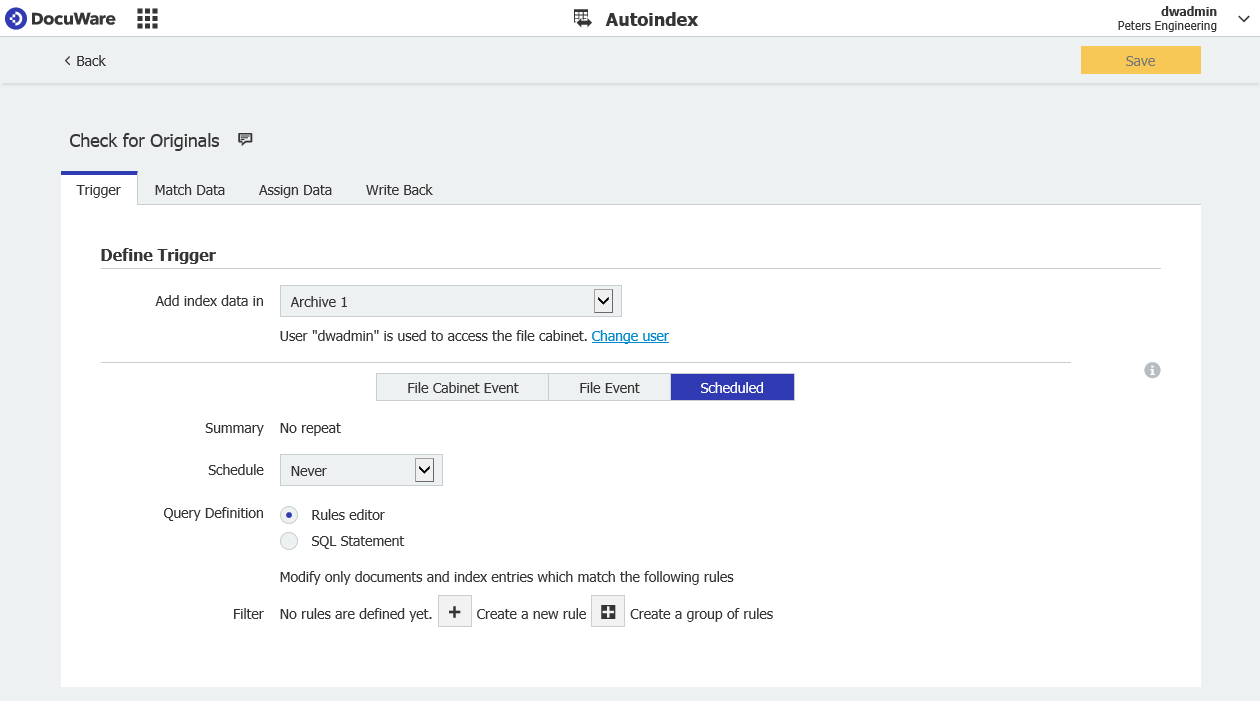
- Comenzaremos creando un trabajo AutoIndex programado como se muestra a continuación.
- En la sección Match Data, seleccione "File Cabinet database" para la fuente, luego elija el nombre del archivador que desea monitorear.
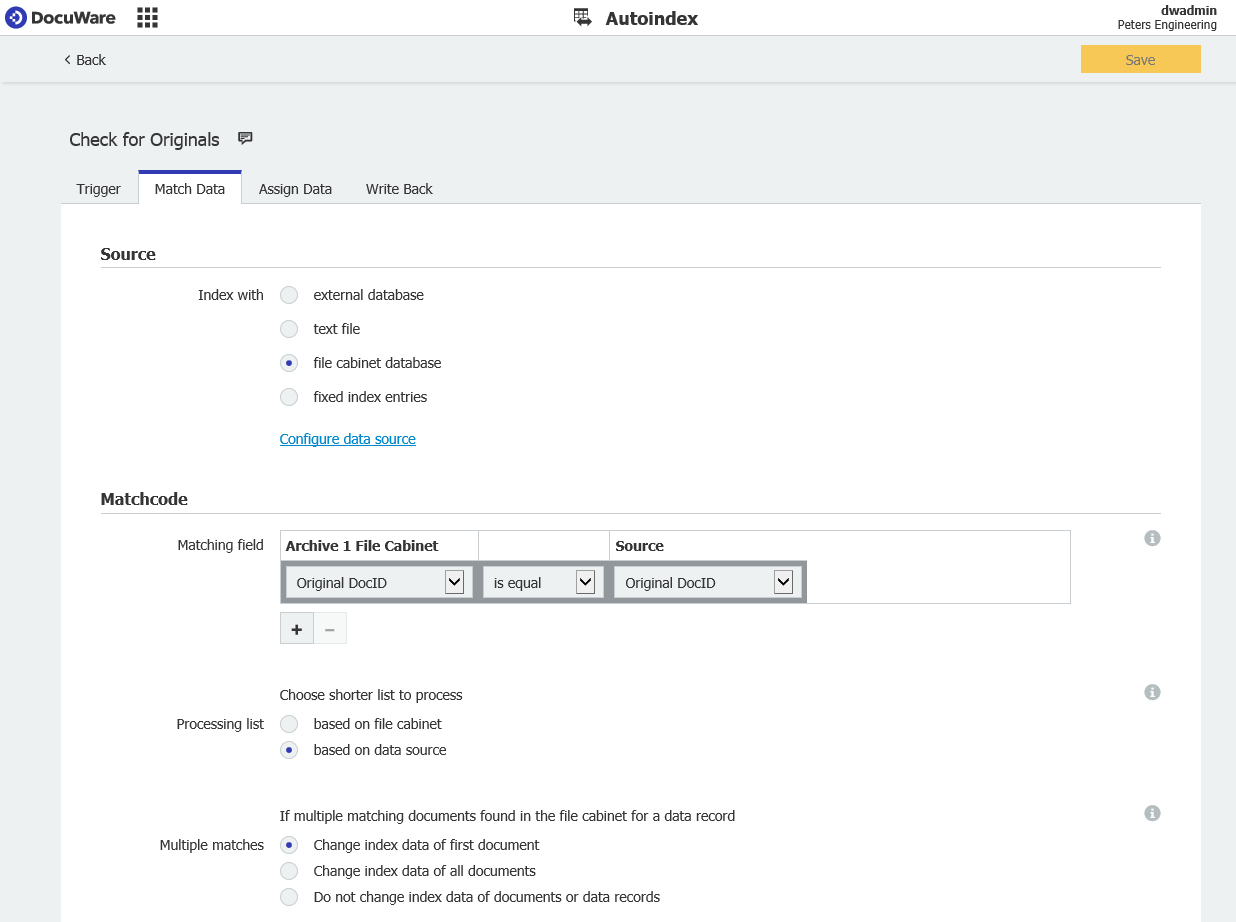
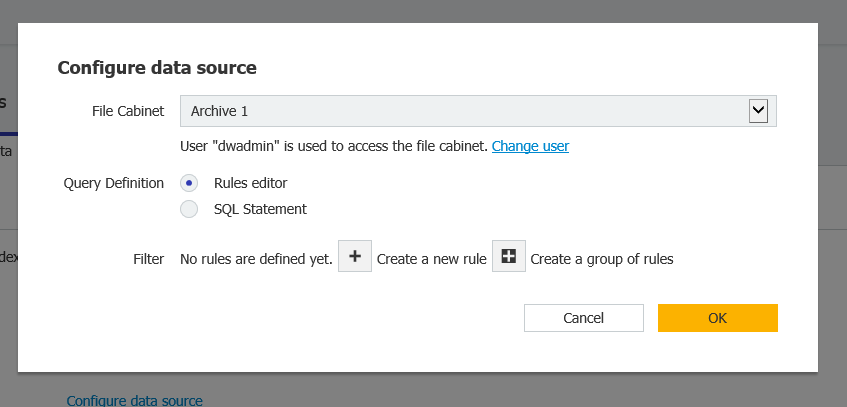
En la sección Matchcode, seleccione "based on data source" de "Processing list" y "Change index data of first document" de "Multiple Searches"
Esto asegurará que en el caso de que encontremos múltiples coincidencias del mismo valor, que sólo actualicemos la primera y la marquemos como la original.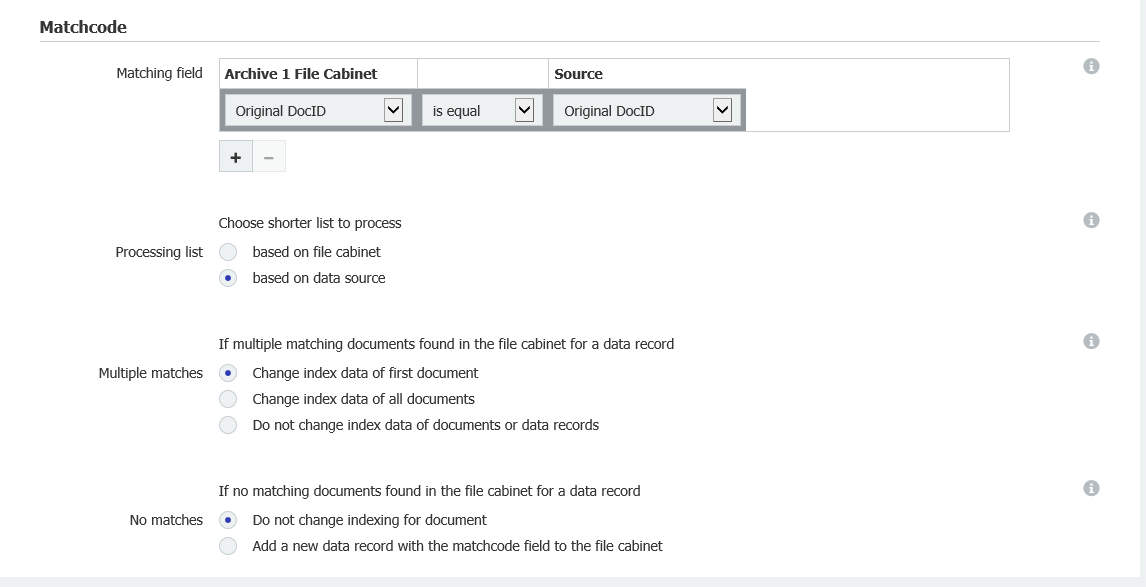
- En Asignar datos, actualice el Estado del duplicado como "Original".
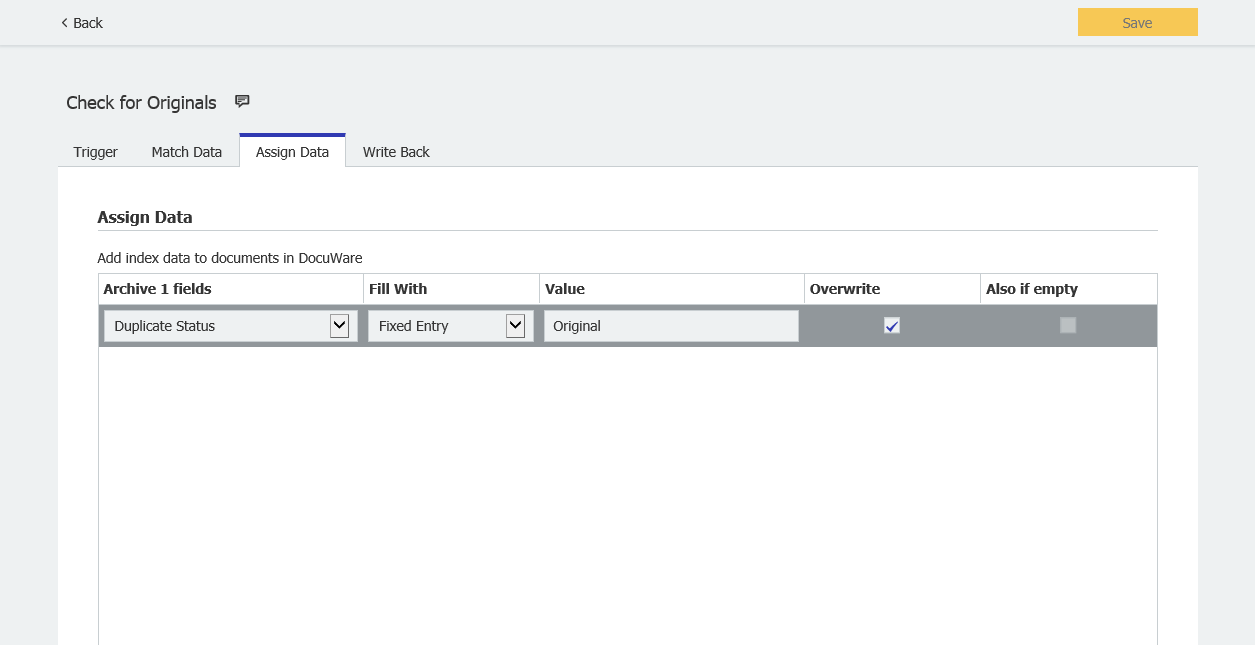
- Guarde los cambios y ejecute manualmente la tarea AutoIndex. Una vez ejecutado, deberíamos ver que la primera instancia de cualquier DocID original encontrado se actualizará con Original y todos los duplicados se han omitido como se muestra a continuación. Podemos proceder a la configuración del flujo de trabajo.
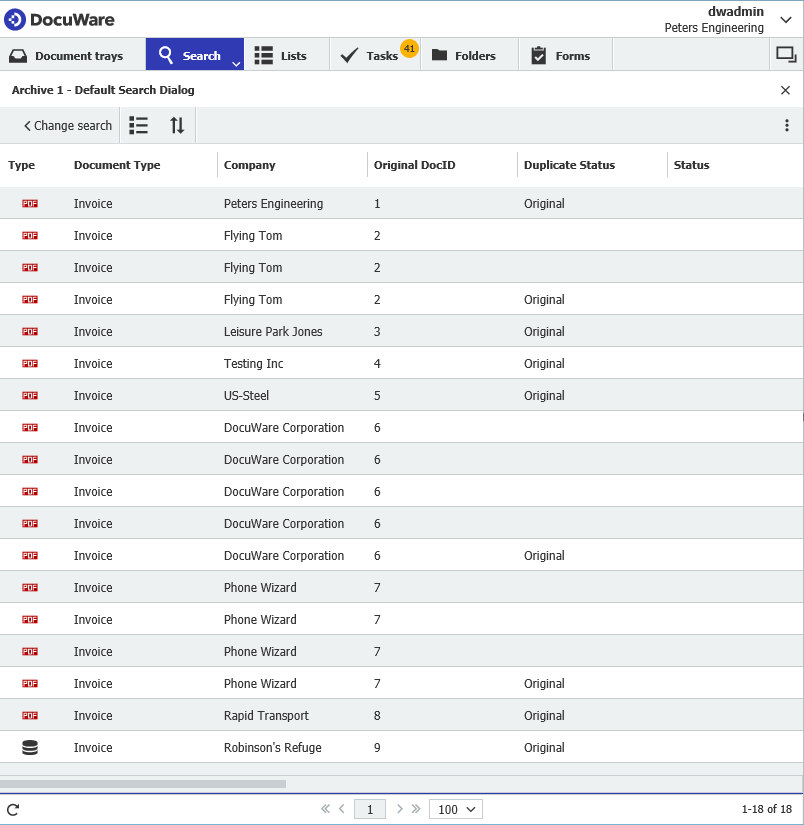
Una vez marcados los originales, la siguiente fase consiste en utilizar el flujo de trabajo para marcar las entradas duplicadas. Un flujo de trabajo configurado para lograr esto es el siguiente,
- Un resumen del flujo de trabajo que se creará tendrá el siguiente aspecto,
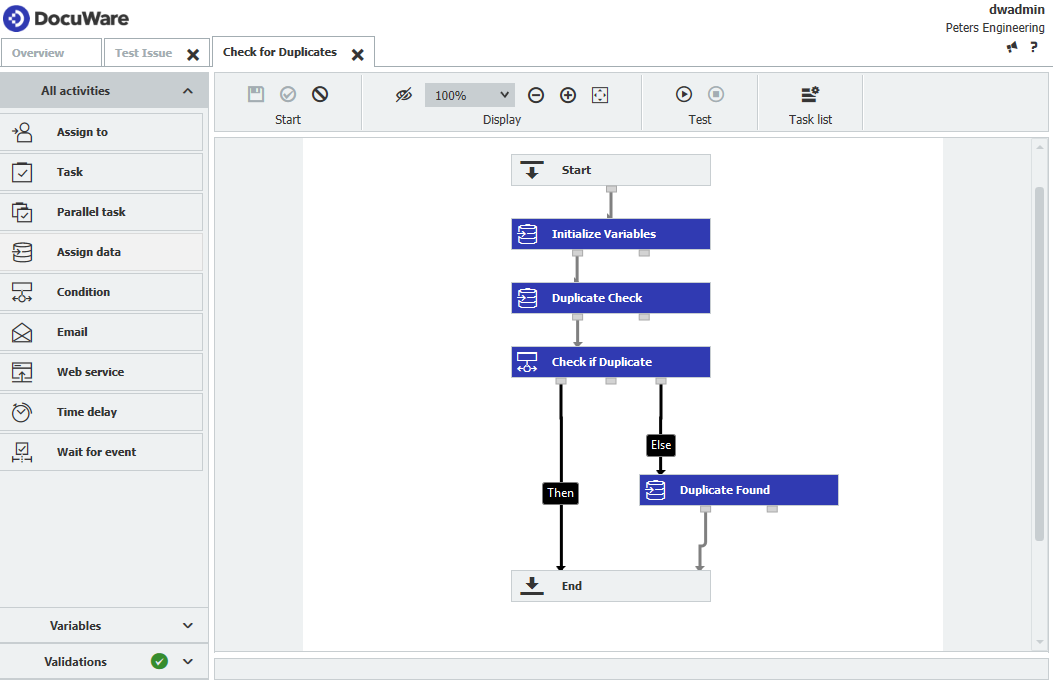
- Las variables a continuación deberán ser creadas para este flujo de trabajo.
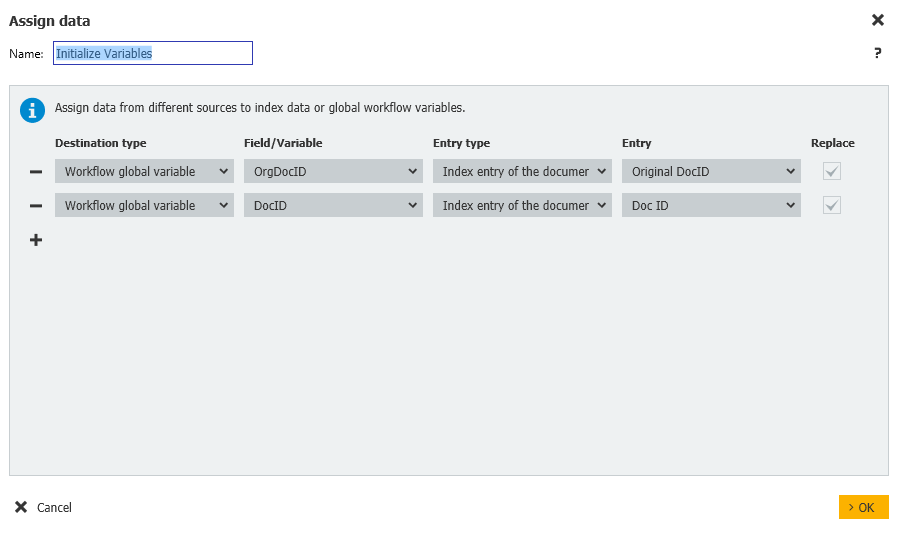
- En nuestro paso Asignar datos, las variables OrgDocID y DocID se inicializan y se asignan a los campos de índice de archivador correspondientes.
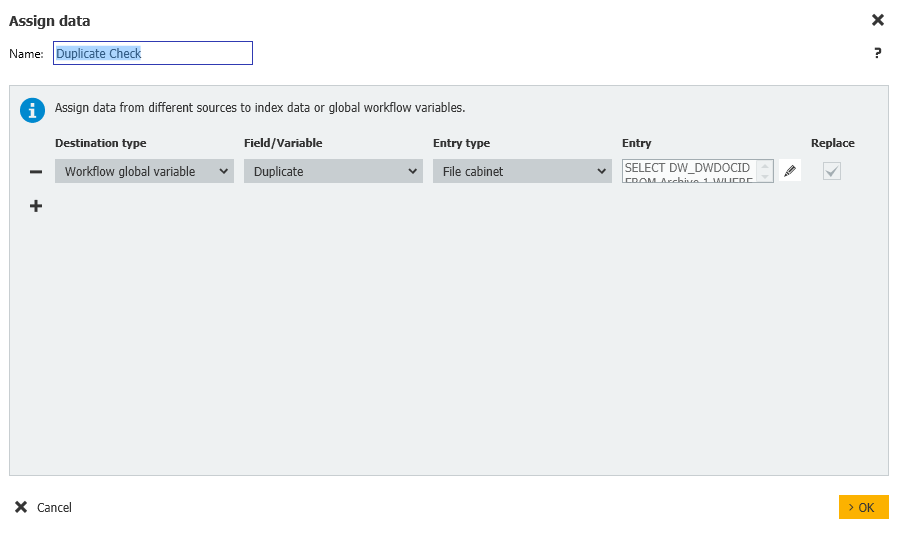
- A continuación, se crea otro paso Asignar datos en el que se inicializa la variable Duplicado y se utiliza una búsqueda del archivador para ver si hay duplicados que marcar.
La sentencia Select en este caso comprobará si hay otras entradas en el archivador que contengan el mismo DocID Original que el documento actualmente en el flujo de trabajo, si el DocID no coincide con el DocID del flujo de trabajo, y finalmente si hay algo en el archivador que haya sido marcado como Original.
Si se encuentra un Original, entonces el documento en el flujo de trabajo será marcado como duplicado.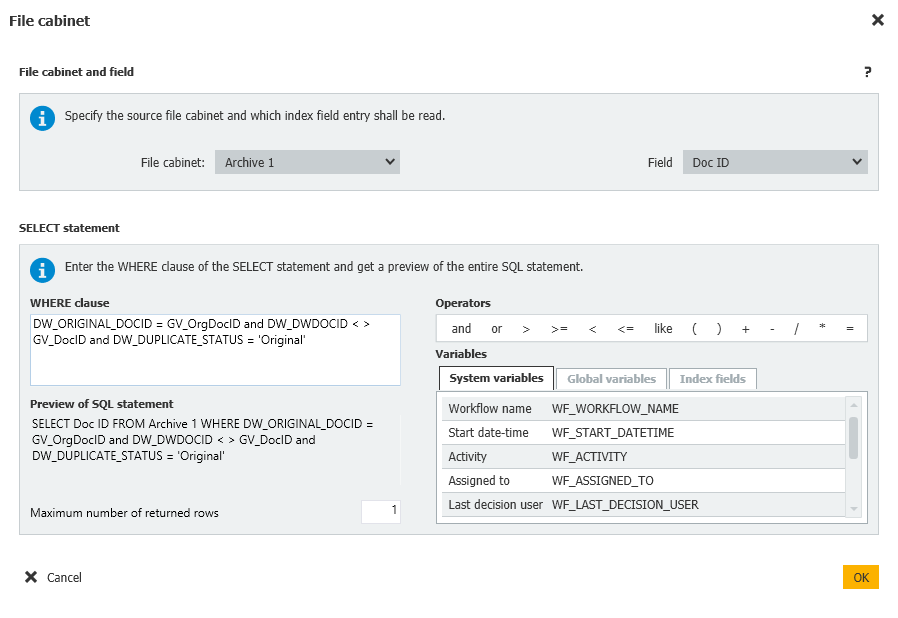
- Una vez que se ha realizado la búsqueda en el archivador, la variable global Duplicado estará vacía o contendrá un valor.
Si se devuelve un DocID, esto indica que se ha encontrado un duplicado. Lo enrutaremos en el flujo de trabajo para que el Estado de Duplicado pueda ser actualizado en consecuencia.
Si la variable global está vacía, entonces saldremos del flujo de trabajo ya que no se necesita nada más.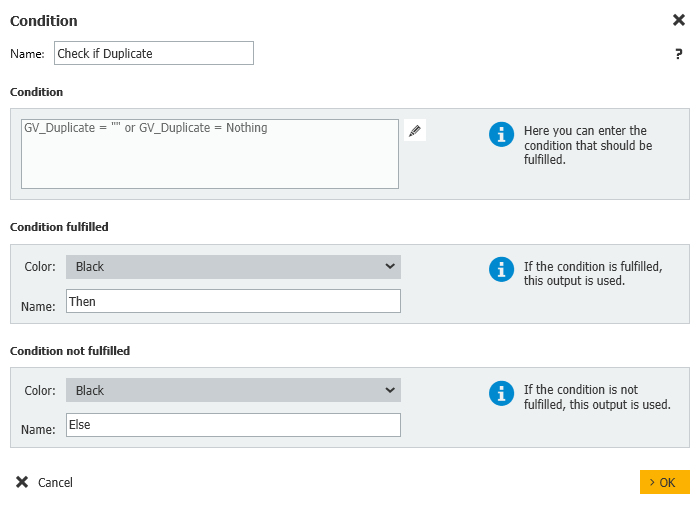
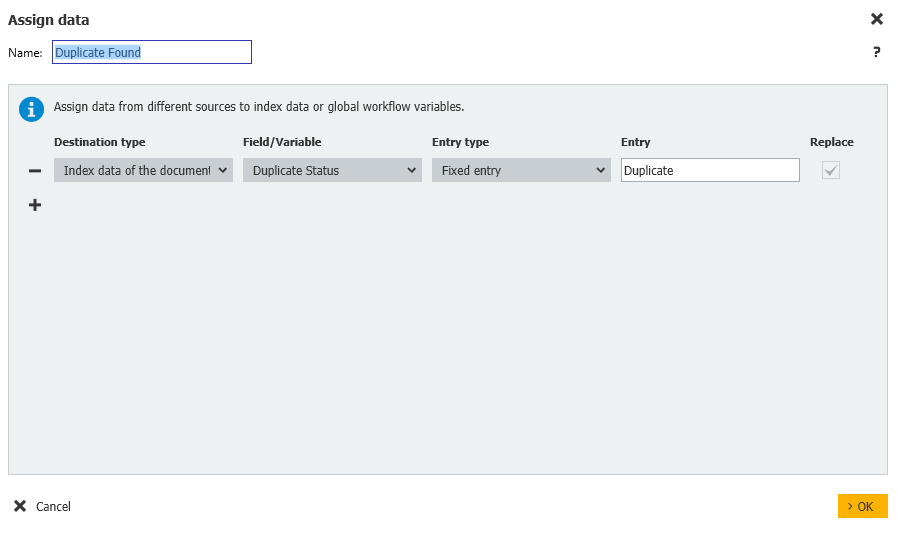
- Si se encontró un duplicado, entonces actualizaremos el campo Estado de Duplicado a Duplicado.
Una vez completado, podemos activar el flujo de trabajo para todos los documentos del archivador. El flujo de trabajo determinará cuál es un duplicado y cuál no, y actualizará el Estado de duplicados en consecuencia. Una vez ejecutado, los resultados serán los siguientes: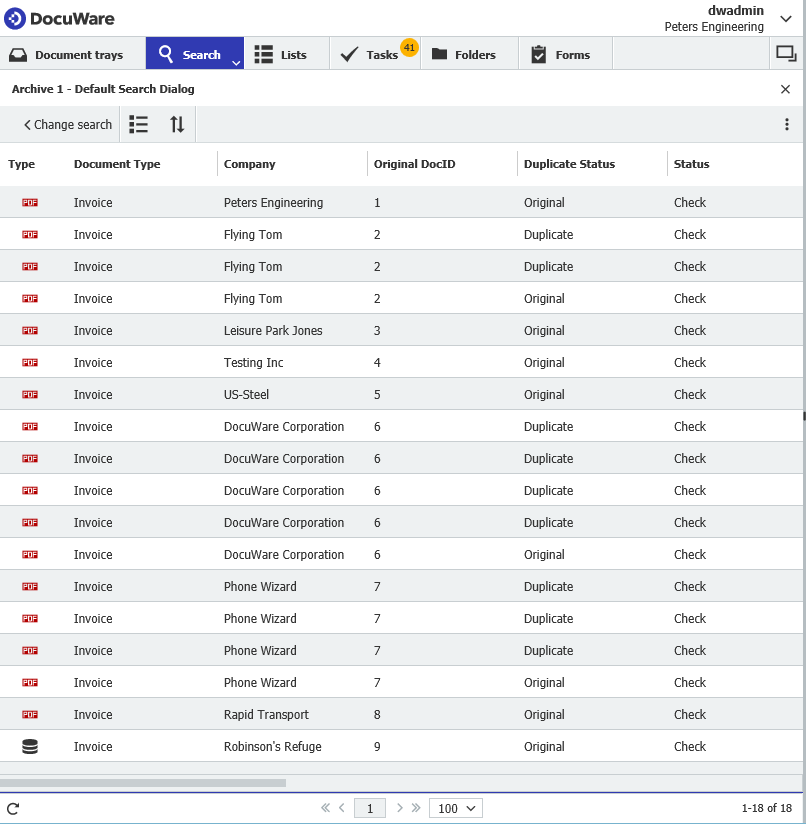
Una vez identificados todos los duplicados, podrá gestionarlos mejor, por ejemplo, mediante una política de eliminación. Encontrará más información sobre la configuración aquí.KBA-36331 - Portal de asistencia DocuWare
KBA aplicable para organizaciones en la nube y locales.
Tenga en cuenta: Este artículo es una traducción del idioma inglés. La información contenida en este artículo se basa en la(s) versión(es) original(es) del producto(s) en inglés. Puede haber errores menores, como en la gramática utilizada en la versión traducida de nuestros artículos. Si bien no podemos garantizar la exactitud completa de la traducción, en la mayoría de los casos, encontrará que es lo suficientemente informativa. En caso de duda, vuelva a la versión en inglés de este artículo.