

Question :
Comment pouvez-vous mettre en place un processus qui signalera les documents dupliqués, qui sont déjà stockés dans une armoire ?
Réponse :
Pour mettre en place ce type de processus, vous pouvez utiliser AutoIndex et Workflow. Veuillez vous référer aux configurations ci-dessous pour un exemple de configuration.
Dans notre scénario, disons que nous avons des documents stockés dans notre armoire et que certains documents utilisent le même "Original DocID" comme indiqué ci-dessous ;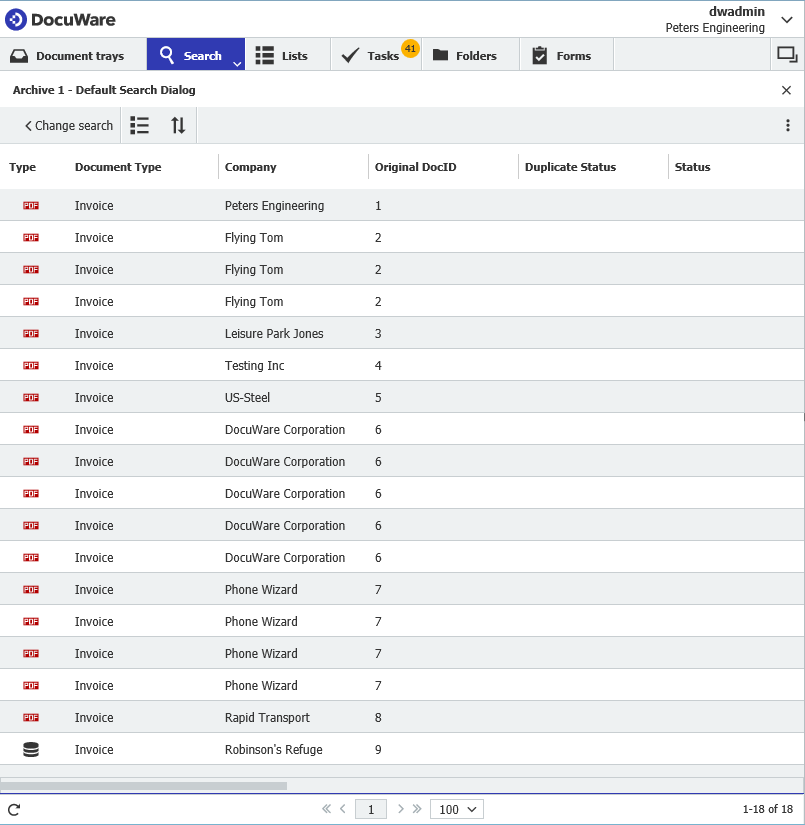
(Note : Pour les besoins de cet exercice, il est recommandé de créer le champ d'index de type texte suivant "Duplicate Status")
La première phase consiste à effectuer une recherche dans l'armoire pour trouver la première occurrence d'une valeur unique qui indiquerait normalement qu'il y a un doublon.
Pour cet exemple, nous utiliserons "Original DocID", où nous vérifierons les documents où le même Original DocID est utilisé.
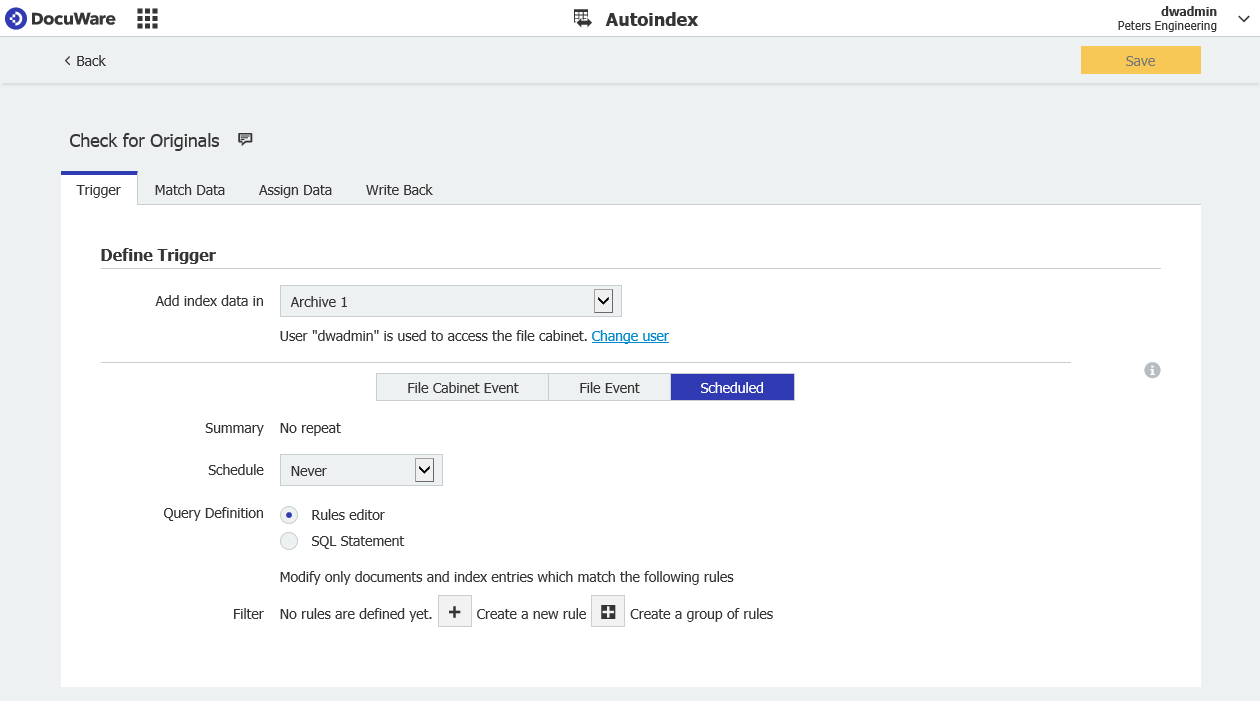
Pour ce faire, nous avons besoin qu'une tâche AutoIndex soit créée, qui utilise la configuration suivante,
- Nous commencerons par créer une tâche AutoIndex programmée, comme indiqué ci-dessous.
- Dans la section Match Data, sélectionnez "File Cabinet database" pour la source, puis choisissez le nom de l'armoire que vous souhaitez surveiller.
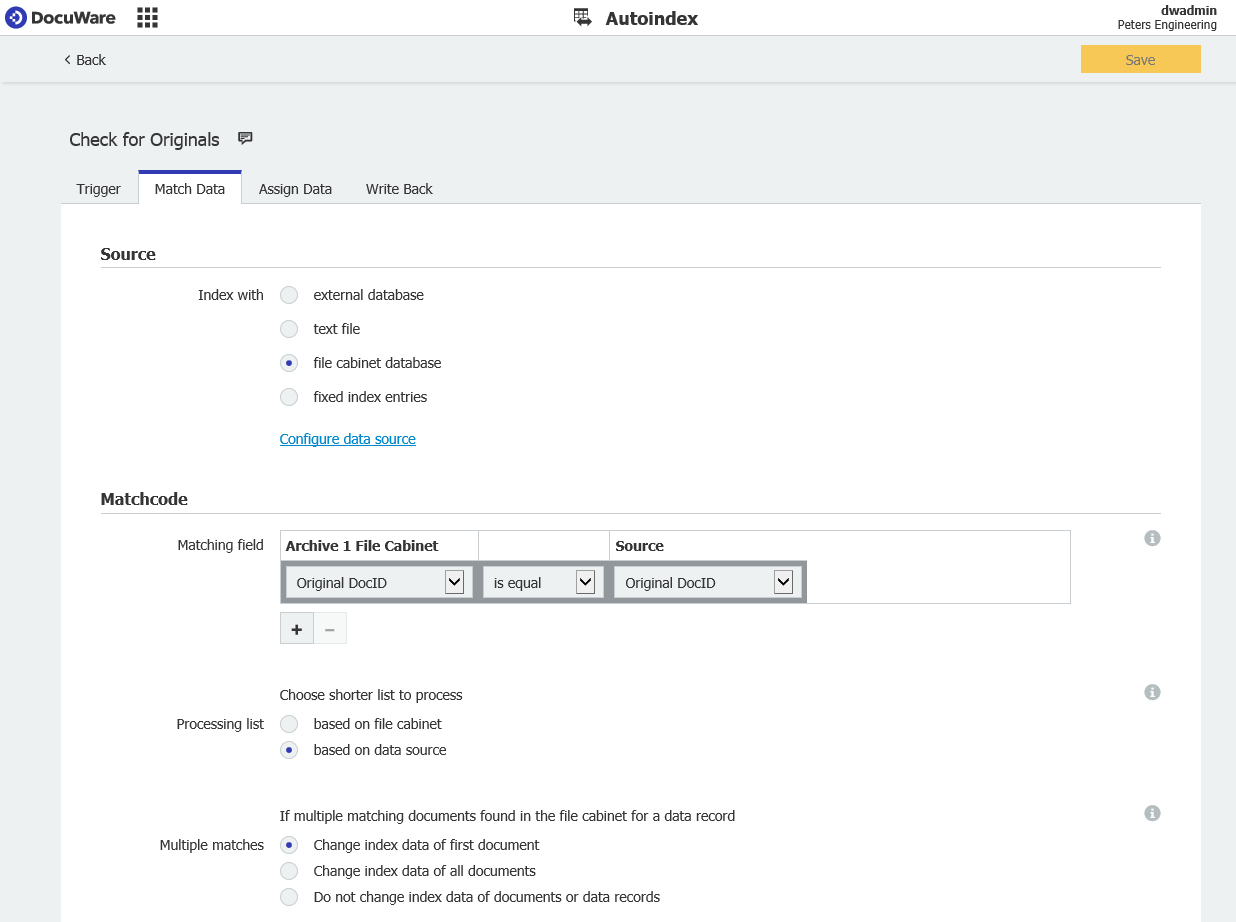
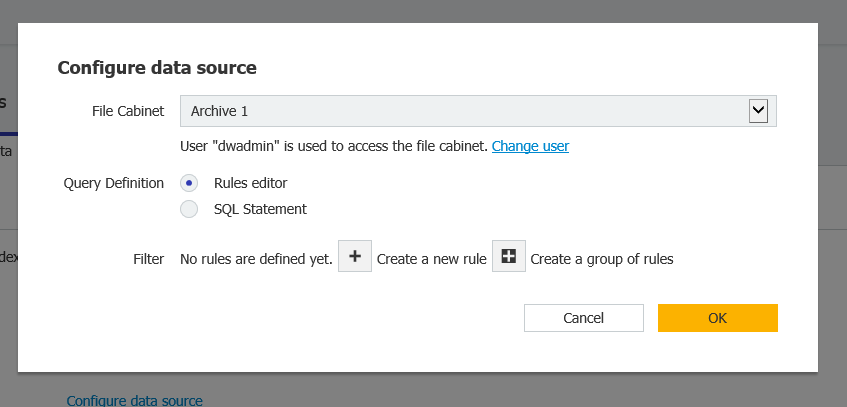
Dans la section Matchcode, sélectionnez "basé sur la source de données" dans "Liste de traitement" et "Modifier les données d'indexation du premier document" dans "Recherches multiples"
Cela permettra de s'assurer que, dans le cas où nous rencontrons plusieurs correspondances de la même valeur, nous ne mettrons à jour que la première et la marquerons comme l'original.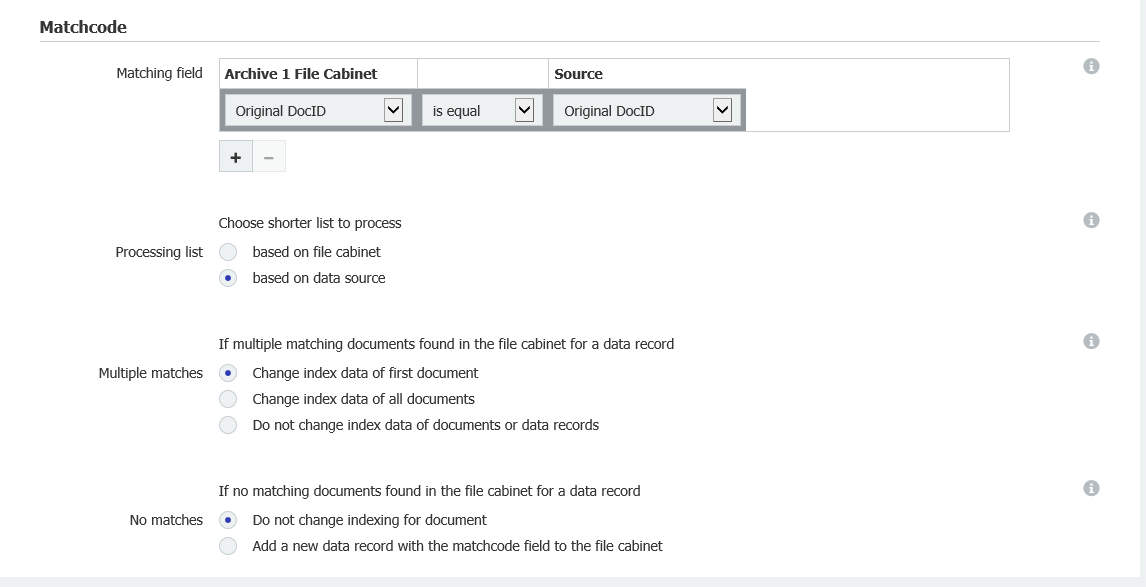
- Dans Attribuer des données, mettez à jour le statut du duplicata en le remplaçant par "Original".
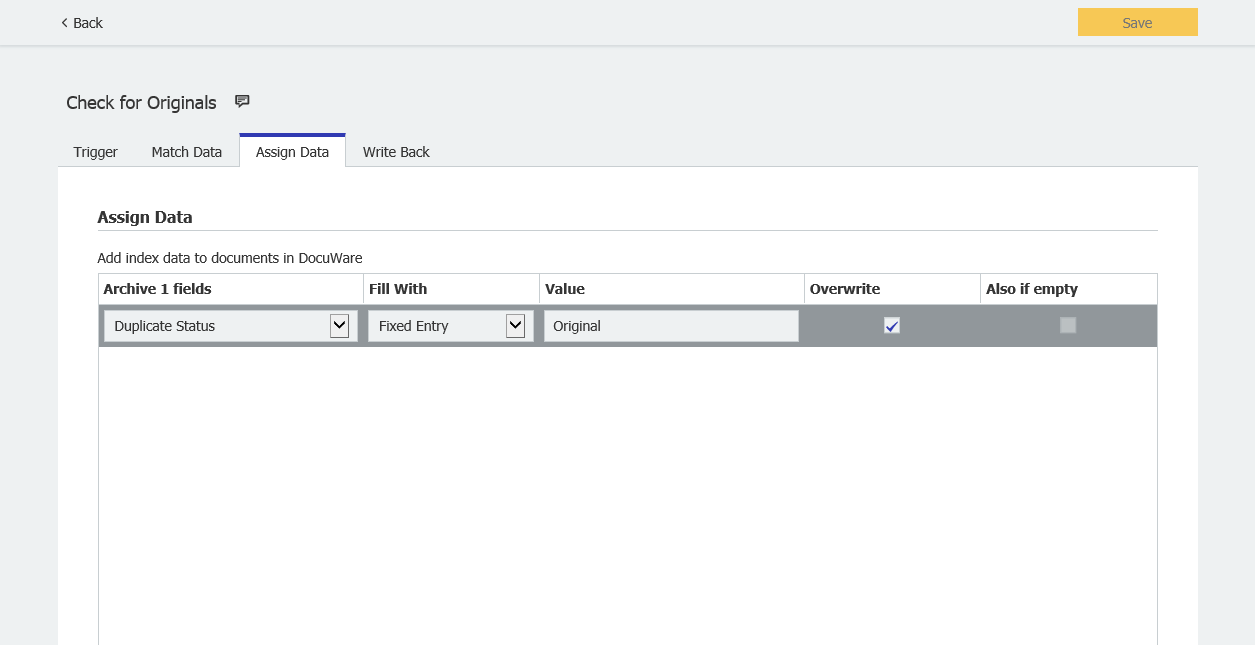
- Enregistrez vos modifications, puis exécutez manuellement la tâche AutoIndex. Une fois la tâche exécutée, nous devrions constater que la première instance de tout DocID original trouvé sera mise à jour avec Original et que tous les doublons ont été ignorés, comme illustré ci-dessous. Nous pouvons passer à la configuration du flux de travail.
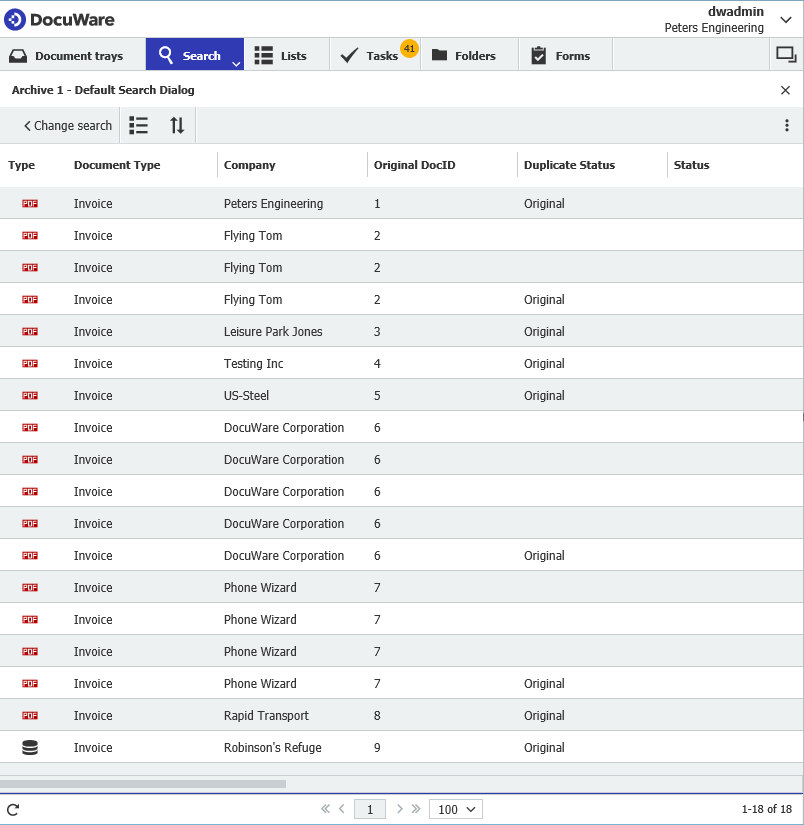
Une fois les originaux marqués, la phase suivante consiste à utiliser le flux de travail pour marquer les entrées en double. Un flux de travail configuré à cet effet se présente comme suit,
- Une vue d'ensemble du flux de travail qui sera créé ressemblera à ce qui suit,
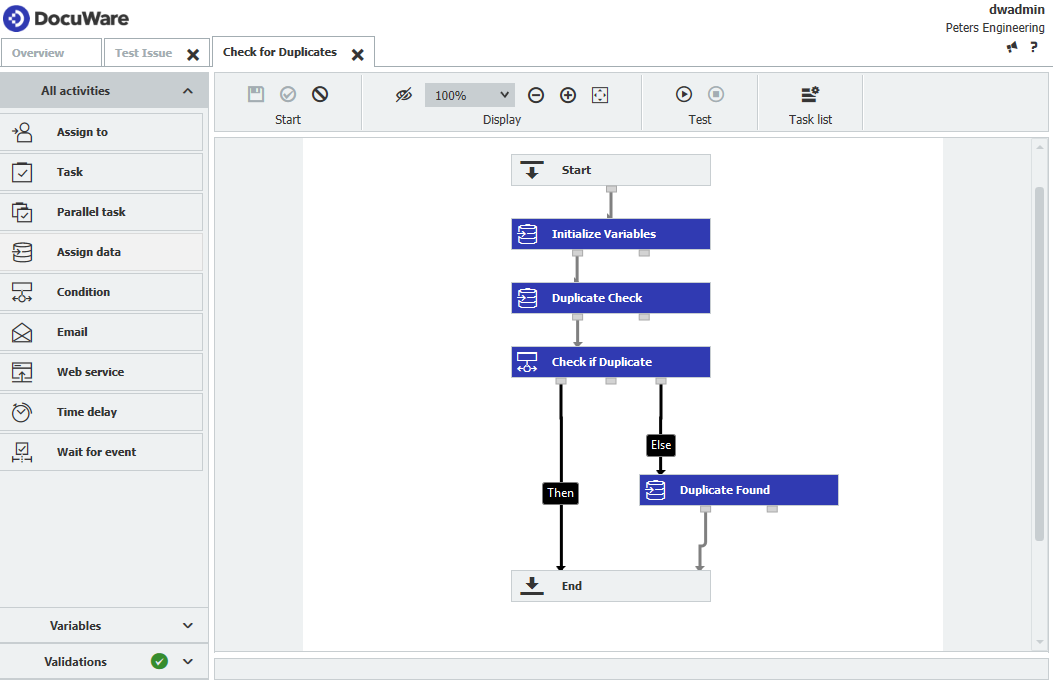
- Les variables ci-dessous devront être créées pour ce flux de travail.
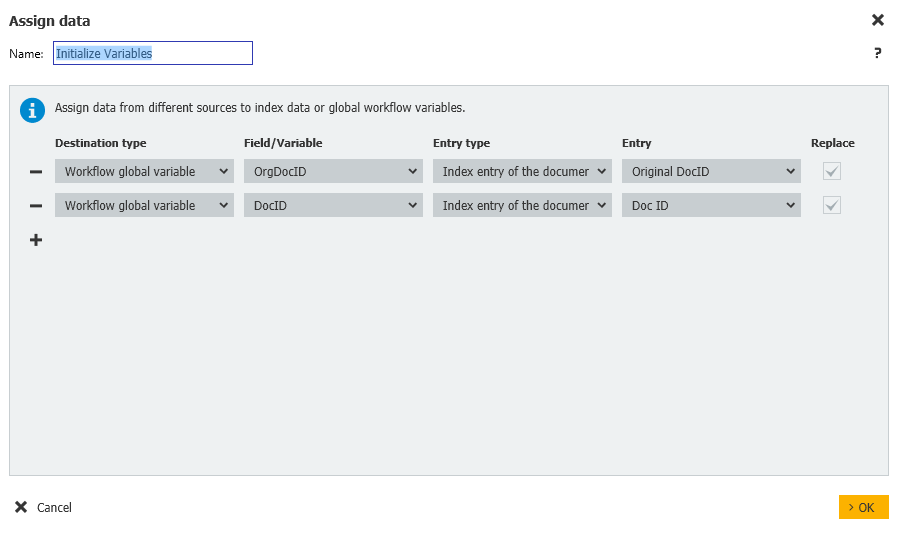
- Dans notre étape d'affectation des données, les variables OrgDocID et DocID sont initialisées et mises en correspondance avec les champs d'indexation correspondants de l'armoire.
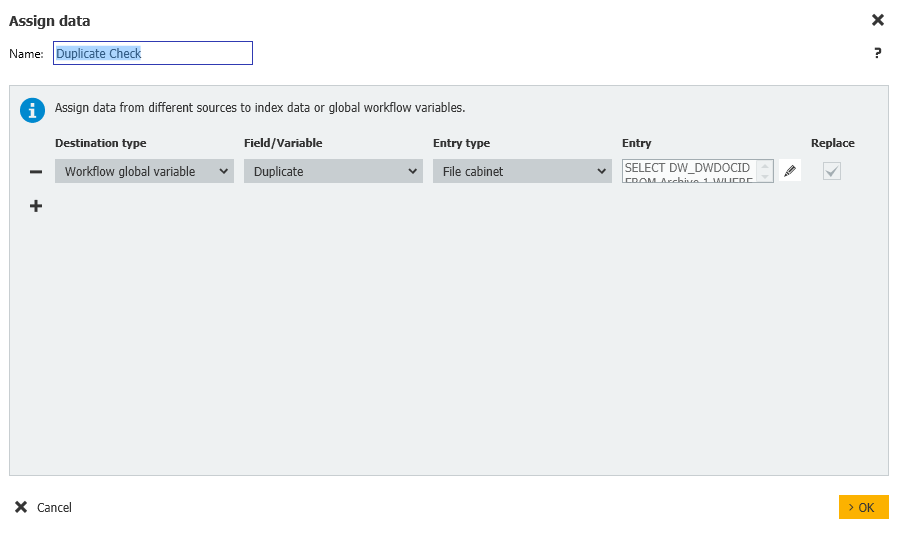
- Ensuite, une autre étape d'affectation des données est créée dans laquelle la variable Duplicate est initialisée et nous utiliserons une recherche d'armoire pour voir s'il y a des doublons à signaler.
Dans ce cas, l'instruction Select vérifiera s'il existe d'autres entrées dans l'armoire contenant le même DocID original que le document actuellement dans le flux de travail, si le DocID ne correspond pas au DocID du document dans le flux de travail, et enfin s'il y a quelque chose dans l'armoire qui a été marqué comme l'original.
Si un original est trouvé, le document dans le flux de travail sera marqué comme un doublon.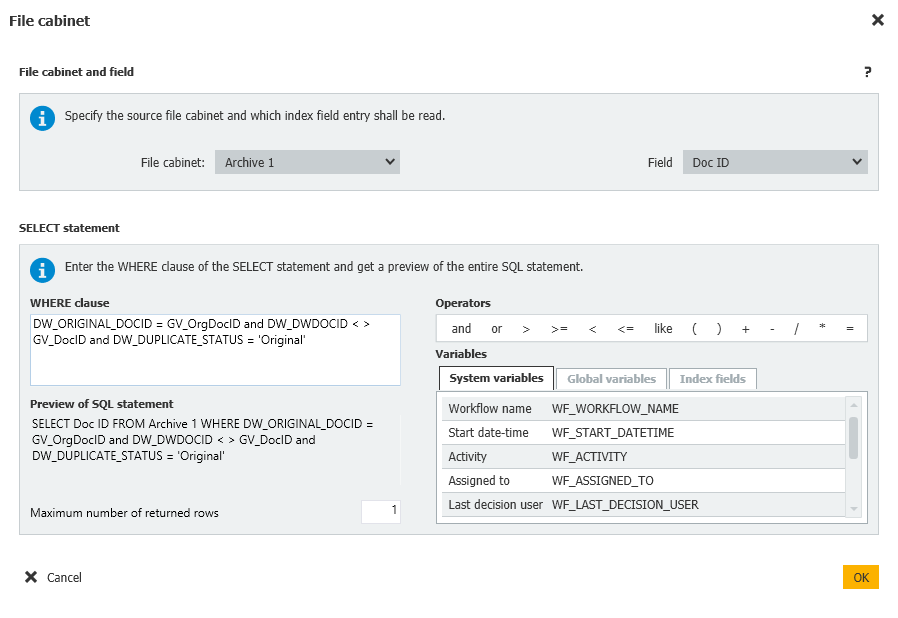
- Une fois la recherche dans l'armoire effectuée, la variable globale Duplicate sera vide ou contiendra une valeur.
Si un DocID a été renvoyé, cela indique qu'un duplicata a été trouvé. Nous l'acheminerons dans le flux de travail afin que le statut du duplicata puisse être mis à jour en conséquence.
Si la variable globale est vide, nous quitterons le flux de travail, car rien d'autre n'est nécessaire.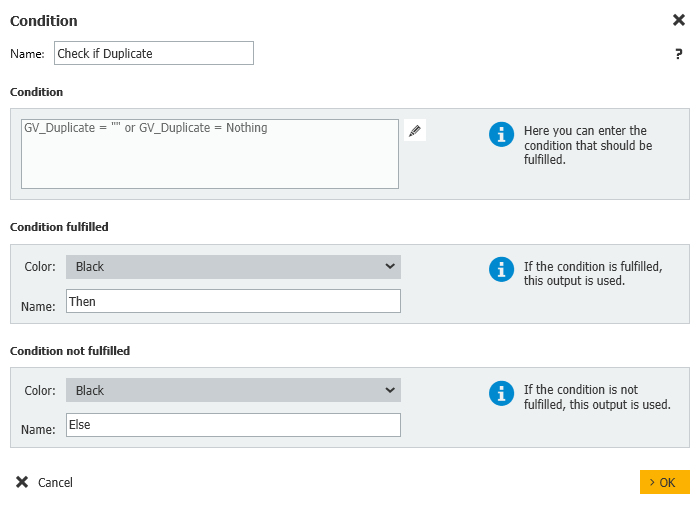
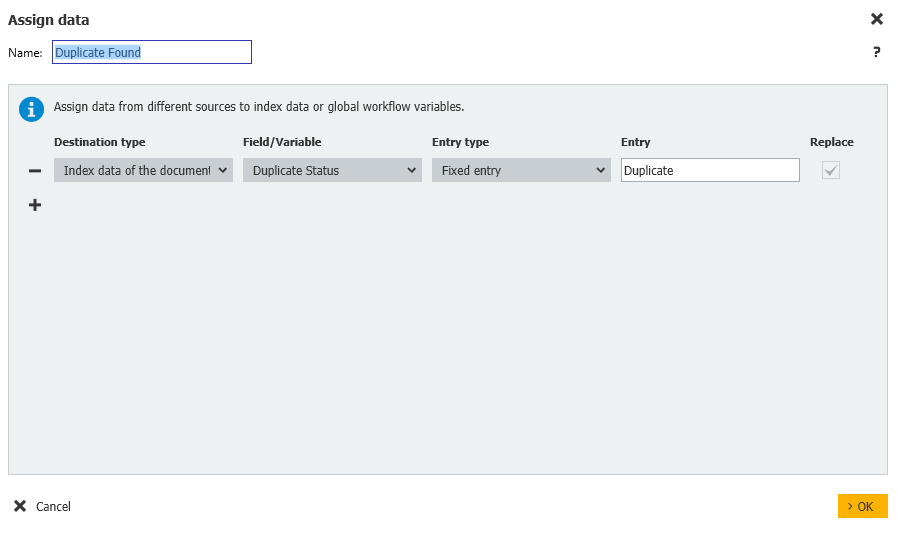
- Si un doublon a été trouvé, nous mettrons à jour le champ Duplicate Status en Duplicate.
Une fois cette opération terminée, nous pouvons déclencher le flux de travail pour tous les documents de l'armoire. Le flux de travail déterminera ce qui est un double et ce qui ne l'est pas, puis mettra à jour le statut du duplicata en conséquence. Après l'exécution de ce processus, les résultats seront les suivants :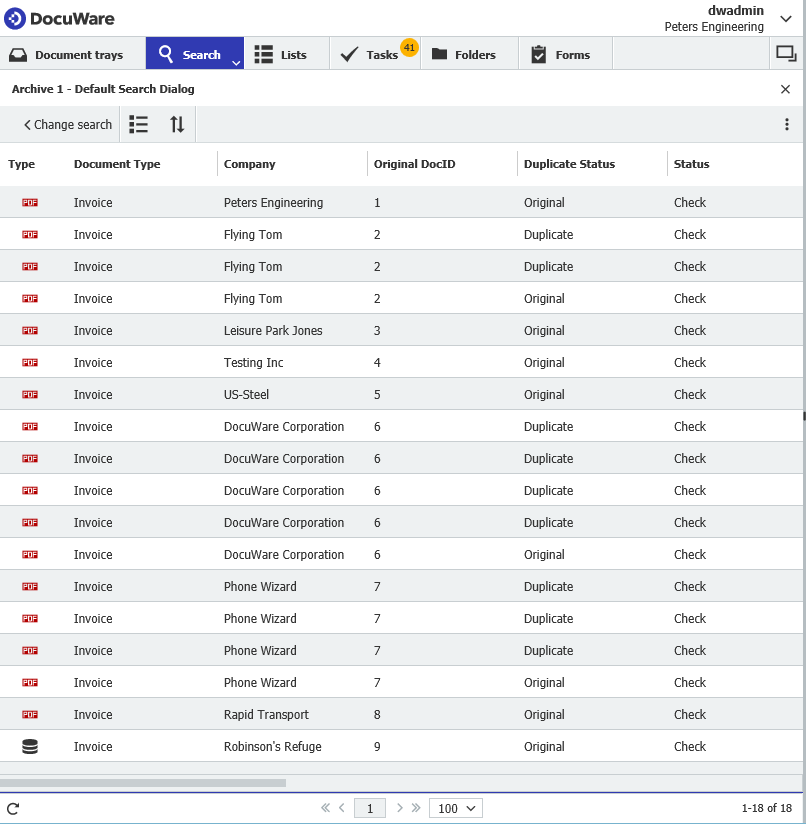
Une fois que tous les doublons auront été identifiés, vous serez mieux à même de les gérer, par exemple en utilisant une politique de suppression. Pour en savoir plus sur la configuration de ce processus, cliquez ici.KBA-36331 - Portail d'assistance DocuWare
KBA applicable aux organisations en nuage et sur site.
Veuillez noter : Cet article est une traduction de l'anglais. Les informations contenues dans cet article sont basées sur la ou les versions originales des produits en langue anglaise. Il peut y avoir des erreurs mineures, notamment dans la grammaire utilisée dans la version traduite de nos articles. Bien que nous ne puissions pas garantir l'exactitude complète de la traduction, dans la plupart des cas, vous la trouverez suffisamment informative. En cas de doute, veuillez revenir à la version anglaise de cet article.